
 C. Alonso, M. Aguado y Y. Arenaza
C. Alonso, M. Aguado y Y. Arenaza
Resumen
El acceso a la información corporativa desde cualquier punto de la organización, en cualquier momento, es una de las piezas claves para el dinamismo de la misma y en la eficiencia en la toma de decisiones. Las personas responsables en la toma de decisiones demandan un acceso rápido y eficiente a la información sin necesidad de conocer el manejo de la aplicación que se encarga de recoger los datos ni de dónde provienen.
Este proyecto nace para cubrir la necesidad de suministrar información compleja, normalmente masiva o estadística, que no es viable ofrecer en un navegador por el tiempo que necesita para su proceso previo. El servidor de información diseñado permite el acceso a la misma con requerimientos mínimos, únicamente se necesita un navegador y un cliente de correo al que se enviará la información elaborada. El proyecto se ha realizado enteramente en Java y, salvo el generador de informes, todas las herramientas empleadas son de libre distribución. Para la realización de este proyecto se ha probado y utilizado Java, Jsp, comunicación entre servidores y servlets, serialización de objetos, pool de conexiones y aspectos de integración de middleware. El proyecto ha sido pensado teniendo en cuenta la escalabilidad y la independencia del tipo de los servidores y de los gestores de bases de datos. Por tanto, se ofrece la posibilidad de tener uno o varios servicios ejecutándose en uno o varios servidores.
Palabras clave: Java, salidas impresas, middleware, aplicaciones web, recuperación de información desde diferentes tecnologías y fuentes
Summary
One of the key values on decision taking is fast access to corporate information at any time, from any place. Decision takers demand a fast and efficient access to information without knowing how to use the application that gathers the data nor where it is stored. This project was designed to offer complex information (high volume of data or statistic one) which it is not advisable to show on a browser due to its long processing time. This information service allows access to information with minimum requirements, just a browser and an email client to receive the requested information. The project was entirely developed in Java and all components are free but the report writer chosen. To accomplish this task we have tested and worked with Java, Jsp, communication between servers and servlets, object serialization, database connection pooling and some other aspects of middleware integration. This project has been designed with scalability and independence from servers and DBMS in mind. So, it is possible to have one or several services running on one or several servers.
Keywords: Java, reporting, middleware, web applications, information retrieval from mixed sources and technologies
1.- Introducción
La evolución que han seguido los desarrollos de aplicaciones informáticas desde el 4gl, cliente/servidor (C/S) y desarrollos en web ha ido acorde con la evolución de las tecnologías de red subyacentes. Inicialmente, el usuario accedía a una aplicación 4gl cerrada, con salidas impresas fijas sin posibilidad de manipulación por su parte. Con la llegada de las aplicaciones cliente/servidor esta situación se flexibiliza dando paso a salidas impresas de mayor calidad, con posibilidad de exportación a formatos manipulables con herramientas ofimáticas ampliamente conocidas. Unida a la mejora de la calidad, la disponibilidad de unos servicios de red cada vez mayores conduce a su vez a una mejora en la facilidad con la que los usuarios pueden acceder a la información. Actualmente la tendencia nos ha llevado a los entornos web, donde el usuario accede a la información desde cualquier punto desde el que tenga acceso a Internet. El uso cada vez más extendido de Internet hace que el usuario se haya acostumbrado a acceder a la información que necesita en cualquier momento, y no sólo dentro de su oficina o empresa. No es necesario tener que instalar ninguna aplicación en el ordenador, tan sólo se necesita un navegador para acceder a la información necesaria.
Este tipo de acceso requiere una respuesta rápida por parte de las aplicaciones diseñadas para acceso vía web. El tipo de conexión no permite (o no es lo adecuado) tiempos de respuesta que superen el minuto o incluso menos. En muchos casos la información requerida puede suministrarse por debajo de ese margen de tiempo y mostrarse en la ventana del navegador. Pero existen otros tipos de información que requieren más tiempo para su elaboración. Un tiempo en el que no es admisible una ventana en blanco en espera de los datos o un timeout antes de recibirlos.
Por otro lado, una asignatura en parte pendiente de las aplicaciones diseñadas vía web son sus salidas impresas. En muchas de ellas las salidas impresas que se pueden obtener están limitadas a la impresión de la pantalla del navegador o del marco actual. El formato no suele ser muy adecuado para muchos documentos que son entregados a un tercero, complejos o con gran cantidad de datos.
En este documento presentamos la solución que hemos llevado a cabo en nuestra universidad para resolver esta problemática.
2.- Entorno
El entorno en el que nos movemos coexisten una mezcla de tecnologías en la que siguen en activo aplicaciones 4gl, junto con desarrollos C/S, a los que ahora se añaden nuevos diseños vía web. En los últimos, de nuevo, los servidores vuelven a realizar la mayor parte del trabajo. Los clientes son ahora navegadores y todo el mundo está acostumbrándose a ellos. Todas las aplicaciones tienen una apariencia similar y no es necesario ningún conocimiento especial para comenzar a utilizar una nueva aplicación. Sea cual sea el entorno en el que están trabajando todos los usuarios perciben la aplicación del mismo modo. Y se puede acceder a la aplicación desde cualquier puesto e incluso desde dispositivos que no son ordenadores.
Para los desarrolladores la nueva situación también tiene grandes ventajas; los desarrollos funcionan en cualquier plataforma, la comunicación entre aplicaciones, servicios y servidores se ha aumentado y simplificado así como los accesos a las bases de datos. Los resultados de este paradigma son tan buenos que no sólo se aplican a nuevos servicios, sino que además se utilizan para ampliar los que ofrecen antiguas aplicaciones diseñadas en 4gl. Coexisten con ellas de una manera transparente, accediendo a su información sin interferir en su funcionamiento.
En nuestro caso el proyecto tenía entre sus objetivos el facilitar el acceso a la información estratégica de la organización que en parte es aún gestionada con aplicaciones 4gl. El acceso rápido y eficiente a la información es uno de los requisitos clave en la toma de decisiones. Hoy en día las personas que tienen tal responsabilidad demandan ese acceso sin conocer los detalles de las aplicaciones que recogen los datos ni su funcionamiento. El acceso vía web a cualquier tipo de información se está convirtiendo en una demanda cada vez más fuerte.
3.- Información compleja
Como se ha mencionado, la toma de decisiones es cada vez más exigente en la rapidez en obtener la información. En muchos casos la información demandada requiere un tiempo de proceso sustancial e incluso puede provenir de varias fuentes. Con lo cual la respuesta no es inmediata. Este tipo de peticiones no encajan bien en el diálogo navegador-servidor de una comunicación http. Si el tiempo de respuesta no fuera motivo suficiente para buscar una solución, la presentación de los resultados
obtenidos lo sería. Presentaciones multicolumnas, con miles de filas nos disuadirían de intentar mostrarlas en pantalla. Si además los datos se piden para unirse o tratarse con otra herramienta, la presentación en pantalla no sería útil.
4.- Navegador + cliente de correo
Junto a la cada vez mayor demanda de información, está la condición de obtenerla en cualquier momento y lugar. Únicamente se cuenta con que los clientes dispongan de un navegador. Mientras que el navegador nos sirve para dialogar con el usuario y recoger sus peticiones, en el punto anterior concluíamos que se hace necesaria otra forma de entregar la información solicitada. En nuestro proyecto la información procesada se envía a través del correo electrónico. Consideramos que el requisito de contar con una cuenta de correo es mínimo y es tan universal como el contar con un navegador. Unos minutos después de solicitar la información el usuario la recibe en su cuenta de correo electrónico.
5.- Java y la generación de informes
La situación actual en el desarrollo de aplicaciones está basada en la utilización de navegadores en su capa de presentación. Sin embargo, estas aplicaciones siguen teniendo su punto flaco en las salidas impresas. La capacidad de impresión de los navegadores es pobre y tiene inconvenientes:
- El resultado es diferente dependiendo de cada navegador y su configuración.
- Los usuarios pueden, por ejemplo, imitar un formulario e imprimirlo, y utilizarlo como si fuera un original.
- Los programadores son los únicos que pueden diseñar listados y cambiarlos.
- Los resultados no pueden exportarse de una manera cómoda a otros formatos.
Al comienzo del proyecto, nuestros nuevos desarrollos y entorno de aplicaciones se encontraban ya en una tendencia clara hacia Java. Por lo tanto era un prerrequisito que la herramienta de generación de informes estuviera a su vez basada en Java. En aquel momento no había muchas y lo que estábamos buscando debía ajustarse a los siguientes requisitos:
- Diseño de informes sencillo y de forma gráfica.
- Los usuarios debían ser capaces de modificar el aspecto final sin requerir conocimientos de programación.
- Necesitábamos que se pudiera ejecutar en cualquier tipo de máquina, es decir, que fuera 100% Java.
- Fácil integración con otros programas o aplicaciones Java.
- Posibilidad de ejecutar los informes tanto en los clientes como en el servidor.
Hasta el momento la herramienta elegida por nosotros ha sido Jreport de Jinfonet. Cubre todos nuestros requisitos e incluso más. Es potente, 100% Java, permite planificación, se puede comportar como un servlet, realiza gestión web de usuarios y control de accesos, etc.
En cualquier caso, el poder elegir otro proveedor es siempre deseable y en nuestro proyecto hemos intentado aislarnos del generador de informes concreto lo más posible de forma que, llegado el caso, el cambio a otra herramienta similar no fuera traumático.
6.- Diseño de la aplicación
6.1.- Planteamiento inicial
Hasta el momento de plantearnos esta aplicación las demandas de los usuarios se habían ido solucionando con aplicaciones Java que suministraban información HTML pura, sin necesidad de instalar nada en la parte cliente salvo un navegador y sin requisitos especiales del mismo; sin necesidad de instalar un plug-in o cualquier otro tipo de "middleware" adicional. De una forma sencilla suministramos al usuario información rápida en su navegador. ¿Pero que ocurre con aquella información que lleva tiempo obtener o procesar? ¿Hay necesidad de diseñar otro tipo de herramienta, otro tipo de aplicación que el usuario debe aprender a manejar? El objetivo era que el usuario pudiera obtenerla de la misma manera, aunque no con la misma brevedad de tiempo, ya que ciertas consultas a la base de datos pueden tardar incluso horas, un espacio de tiempo que el usuario no puede estar esperando. De ahí surgió el planteamiento de nuestro diseño que, unido a una herramienta de generación de informes, entrega al usuario los resultados por correo electrónico.
6.2.- Diseño
El diseño de la aplicación se ha llevado a cabo buscando la mayor modularidad posible. Teniendo en cuenta que la información puede estar distribuida en diferentes bases de datos, diferentes gestores de bases de datos y diferentes servidores, la modularidad nos permitirá distribuir el trabajo de forma que se consiga el mayor paralelismo de ejecución posible, evitando siempre que se pueda los cuellos de botella.
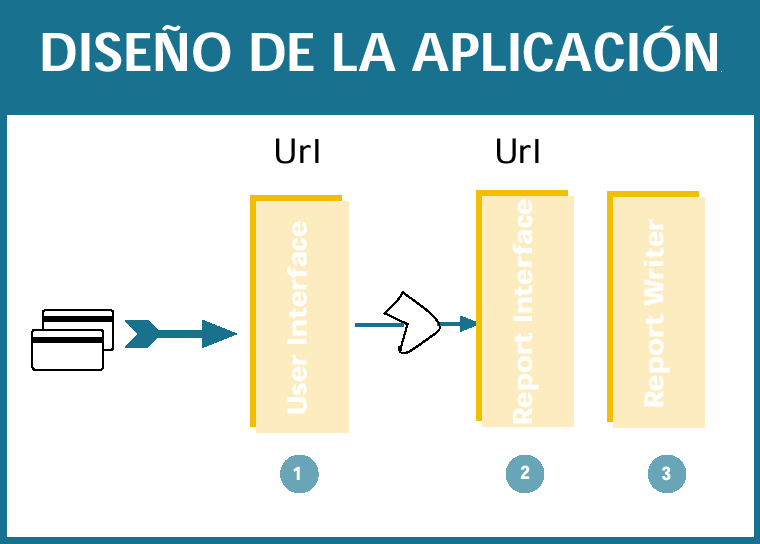 La aplicación se ha diseñado en 3 módulos:
El primer módulo es el responsable de
identificar y autentificar a los usuarios.
La aplicación se ha diseñado en 3 módulos:
El primer módulo es el responsable de
identificar y autentificar a los usuarios.
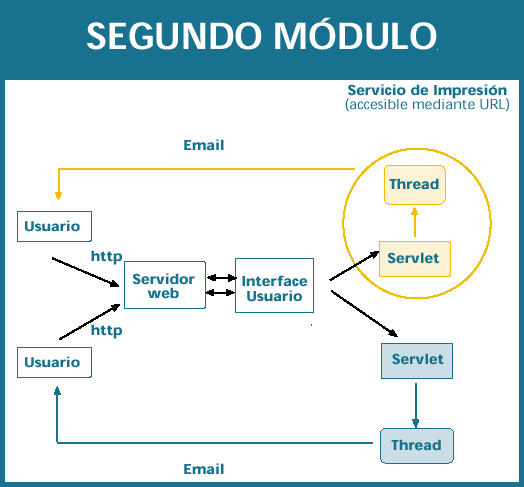
Dependiendo de los permisos de cada usuario, mostrará en pantalla sus posibles opciones y enviará al siguiente módulo sus peticiones. A su vez, indicará al usuario que la información solicitada la recibirá por correo devolviéndole el control de la aplicación y su navegador sin esperas innecesarias. Las páginas presentadas al usuario se generan, en su mayoría, dinámicamente mediante Jsp. No es necesario diseñar una pantalla por cada listado disponible. La aplicación genera la pantalla de captura de peticiones y los parámetros para la obtención del informe dinámicamente.
El segundo módulo es el encargado de procesar y transformar las peticiones en parámetros con el formato que el generador de informes necesita. Este módulo es una capa para aislar la aplicación propiamente dicha del generador de informes. Si en el futuro el generador de informes cambiara, y con ello el formato de las peticiones, sólo será necesario retocar este módulo. Cada petición es atendida por un thread, de forma que pueden gestionarse varias a la vez. En este módulo se puede implementar la gestión de colas que se desee, asíncronas, fifo, etc.
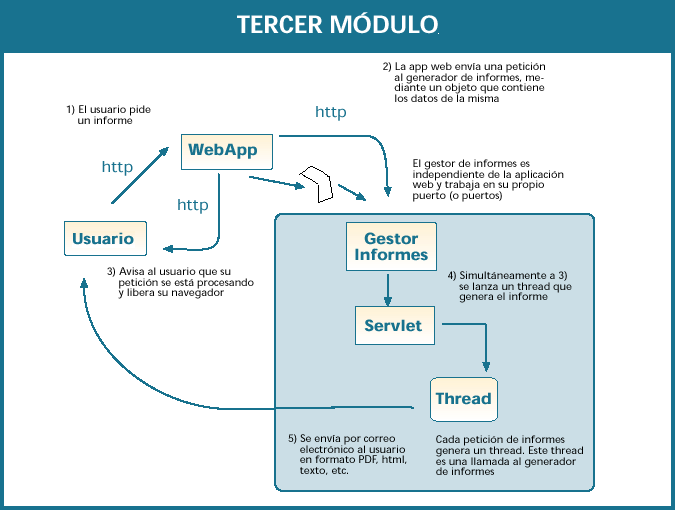
 El tercer módulo
es el generador de informes
propiamente dicho, que a su vez puede estar
escuchando las peticiones en una URL
independiente. Este diseño modular nos
permitirá en el futuro distribuir el trabajo en
varios servidores. En el momento en que el
número de peticiones desborde al servidor,
bastará con arrancar otra instancia del
generador de informes en otro puerto o en
otro servidor para aumentar el paralelismo.
El tercer módulo
es el generador de informes
propiamente dicho, que a su vez puede estar
escuchando las peticiones en una URL
independiente. Este diseño modular nos
permitirá en el futuro distribuir el trabajo en
varios servidores. En el momento en que el
número de peticiones desborde al servidor,
bastará con arrancar otra instancia del
generador de informes en otro puerto o en
otro servidor para aumentar el paralelismo.
7.- Resultados y conclusiones
Una de las ventajas de trabajar con Java es que sin grandes medios se puede empezar a trabajar en una solución y si produce resultados puede implantarse sin retoques a gran escala.
Implementado con PCs asequibles y Linux, se ha instalado sin cambios en servidores de producción. Sin modificaciones puede funcionar con servidores web de libre distribución como Tomcat o con servidores de aplicaciones como Iplanet. Creemos que hemos logrado nuestro objetivo de cubrir un hueco en la necesidad de información inmediata con una solución modular y escalable que puede funcionar si es necesario en entornos modestos. Los usuarios cuentan con un punto unificado y homogéneo para sus necesidades de información, independiente de la localización de los datos, gestores de bases de datos y los sistemas operativos que los soportan.
8.- Agradecimientos
Además de la colaboración del resto de compañeros de nuestro Servicio Informático, queremos agradecer la colaboración de los usuarios que han participado en las pruebas. También a todas las personas que trabajan en proyectos como Tomcat o Linux que nos brindan potentes herramientas sin coste alguno. Y en especial a aquellos que participan en listas y foros de discusión dedicando tiempo y compartiendo sus conocimientos con otros, sin los cuales, proyectos como este nunca verían la luz.
9.- Referencias
[1] Niemeyer P. and Peck J. Exploring Java, O'Reilly & associates. ISBN 1-56592-184-4
[2] Schumer L and Negus C., Using Unix. Que Corp. ISBN 0-07897-253-3
[3] Orfali R. and Harley D. Client/Server Programming with Java and Corba. John Wiley & Sons. ISBN 0-471-16351-1
[4] Bergsten Hans, Improved Performance with a Connection Pool.
http://WebDevelopersJournal.com/columns/connection_pool.html
[5] The Jakarta Project. SubProject Tomcat. http://jakarta.apache.org.
[6] Java Server Pages TM Technology. http://java.sun.com/products/jsp/
[7] Java TM 2 Enterprise Edt. http://java.sun.com/j2ee/
[8] The Apache Jserv Project. http://java.apache.org/
[9] Jinfonet Software Inc. http://www.jinfonet.com/
[10] Philion P. Build servlet-based enterprise Web applications.
http://www.javaworld.com/javaworld/jw-12-1998/jw-12-servlethtml_p.html
(losalo@unavarra.es)
Jefe de la sección de Gestión
Maite Aguado Ruiz,
(maite.aguado@unavarra.es)
Gestor de Servicios Informáticos
Yolanda Arenaza Sarasola,
(yas@unavarra.esi)
Técnico de Servicios Informáticos
Universidad Pública de Navarra
Servicio Informático