
 V. Luque Centeno, C. Fernández
Panadero, C. Delgado Kloos, A. Marín López, C.
García Rubio
V. Luque Centeno, C. Fernández
Panadero, C. Delgado Kloos, A. Marín López, C.
García Rubio
Resumen
La información de los grandes medios de comunicación (prensa, radio, televisión) se ha caracterizado desde su nacimiento por una característica común: la elaboración de información y su posterior difusión al público en general. Teniendo en cuenta la gran diversidad de intereses que existe entre los miembros de una comunidad, muchas han sido las redacciones de los periódicos que han deseado poder hacer llegar a cada uno de sus lectores una versión personalizada de su diario impreso. Lamentablemente, para la gran mayoría de los periódicos es imposible tener una imprenta que genere ejemplares personalizados de forma que se les haga llegar cada mañana a sus respectivos lectores. Sin embargo, las nuevas tecnologías como Internet sí permiten realizar servicios telemáticos como el que hemos abordado con nuestro proyecto: un periódico electrónico personalizable.Introducción
Tradicionalmente, los navegadores de Internet o browsers han sido considerados como meras herramientas de visualización de documentos. La única interactividad que permitían al usuario consistía en la ejecución de programas en el lado del servidor (programas CGI) que eran invocados tras rellenar un formulario HTML. La aparición de los applets de Java y los guiones de JavaScript ha permitido que parte de esa interactividad pueda ser ejecutada en el navegador del cliente sin que exista interacción con el servidor. Últimamente han aparecido en la red numerosos ejemplos de páginas Web que sorprendían a los internautas al posibilitarles la interacción del usuario con el documento en aplicaciones prácticas de lo que se ha venido a llamar HTML dinámico. El principal atractivo de HTML dinámico es que permite que los guiones de JavaScript puedan tratar el documento como un modelo de objetos programables. El grado de control que desde JavaScript se puede realizar sobre estos objetos que se corresponden con partes del documento es tan grande que es posible encontrar páginas Web consistentes en juegos, tutoriales de enseñanza o aplicaciones sencillas como pequeñas hojas de cálculo y todas ellas escritas en muy pocas líneas de código fuente.Aunque la personalización de servicios telemáticos no es nueva en Internet, lo cierto es que hasta ahora, esta personalización estaba basada en la ejecución de programas CGI en el servidor que daban el servicio personalizado a quien lo solicitaba. Sin embargo, la ejecución de estos programas CGI suponen un consumo de recursos que pueden limitar el número máximo de accesos simultáneos al servidor, por lo que ha habido tradicionalmente bastantes reservas a utilizar este tipo de solución como método de proporcionar servicios telemáticos a usuarios de forma individual, sobretodo en servidores donde el número de accesos concurrentes es bastante elevado. Conviene por tanto intentar repartir esta carga computacional entre el servidor y el cliente, de forma que las rutinas que deban ser ejecutadas en el servidor sean ejecutadas en el servidor y que las rutinas que puedan ser ejecutadas en el cliente puedan ser ejecutadas en el cliente. Nuestro proyecto consiste en la elaboración de un sistema telemático (un periódico electrónico) que, a diferencia de los actuales, incluya una capacidad de personalización constante y continua y que permita llevar a cabo un aprovechamiento óptimo de recursos haciendo uso de la capacidad computacional del ordenador del cliente y minimizando el trasiego de información redundante por la red.
La personalización no es un requisito imprescindible para usar nuestro periódico. Siempre será posible una lectura del mismo sin personalización. La medida de éxito de nuestro proyecto se basará precisamente en el grado de aceptación que los lectores hagan de nuestro servicio de personalización en lugar de acceder a la información de una forma anónima sin personalizar.
Diseño del sistema
A continuación de la figura 1 se enumeran las características más importantes de los elementos que la integran.
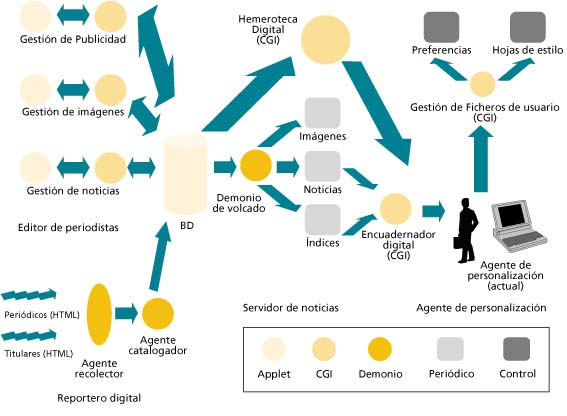
Editor de periodistas
El editor de periodistas consiste en una aplicación Java ejecutable también como applet cuya labor primordial radica en la edición de las noticias del periódico electrónico. Al ser a la vez un applet y una aplicación, es posible ejecutarlo tanto de forma independiente en una máquina con plataforma Java como en un navegador Web. Está compuesta por una ventana de edición y varios botones y menús que permiten insertar de forma cómoda para el periodista las etiquetas de marcado que se consideren oportunas así como sus atributos. Al terminar su edición, la noticia es insertada en una base de datos alojada en el servidor. Durante la redacción de la noticia, el periodista puede ir guardando versiones temporales de su trabajo tanto en el disco duro de su ordenador como en el mismo servidor. El cliente de periodistas se encuentra disponible en cuatro versiones diferentes: una para la gestión de noticias, otra para la gestión de imágenes, otra para la gestión de publicidad y otra última para la gestión de plantillas de presentación. Aparte del interfaz de edición incorporado, el cuerpo de la noticia puede ser editado con cualquier herramienta externa del gusto del periodista.
Base de datos
La base de datos es el repositorio natural de la información publicada por el periódico. En ella se almacenan todos los elementos multimedia que forman parte de las noticias (texto, audio, vídeo, imágenes, ...). Con el fin de permitir un fácil reemplazamiento de este componente, el sistema realiza exclusivamente accesos a través de consultas SQL estándar de bases de datos relacionales mediante conexiones ODBC, lo cual permite a su vez, utilizar un gran número de bases de datos disponibles de diversos fabricantes. Actualmente, nuestro prototipo utiliza una base de datos de libre distribución llamada mysql y que se encuentra disponible en nuestra plataforma de pruebas: una red de estaciones Linux.
Demonio de volcado
El demonio de volcado consiste en una aplicación de ejecución periódica que vuelca los contenidos más recientes de la base de datos a ficheros en formato HTML que puedan ser directamente entregados al cliente por el servidor de Web.
Reportero digital
Además de las noticias elaboradas en la redacción del periódico digital mediante el uso de nuestro cliente de periodistas, el lector puede estar interesado en otras fuentes de información, como la que pueden ofrecer a su vez otros periódicos electrónicos de la red. Aunque la idea de hacer referencias bibliográficas de unos periódicos a otros es impensable para las ediciones impresas en papel, lo cierto es que no sólo la tecnología del hipertexto lo hace posible, sino que además lo hace aconsejable. En Internet se dice que tan valioso o más que ofrecer información es ofrecer el camino que lleva hasta ella. Así, uno de nuestras decisiones de diseño consiste en ofrecer al lector la posibilidad, no sólo de profundizar contenidos hilvanando la lectura de noticias relacionadas, sino también de contrastar esos contenidos con las versiones que publican otros medios, agrupando esas referencias en torno a las noticias publicadas por nuestro diario.
Bien sea por la declaración explícita por parte del periodista de la redacción del periódico digital o por la detección automática a través de nuestro agente catalogador (con criterio aceptable, aunque menos fiable que el anterior), las noticias que forman parte del periódico acaban por tanto acompañadas de una lista de temas o palabras clave que permiten, entre otras cosas:
- Agrupar las noticias de una misma sección por temas afines o subsecciones. Nuestro prototipo actual incluye muchas noticias dentro de la sección de un día (entre menos de 10 hasta alrededor de más de 100) y, al no tener implementado el agente catalogador, las noticias aparecen sin clasificar causando una cierta sensación de desorden. De esta forma, cuando esté operativa la clasificación por subsecciones no será necesario buscar noticias relacionadas a una dada en toda su sección, sino sólo en su misma subsección.
- Incluir referencias de las noticias en todas y cada una de las secciones o subsecciones en las que la noticia tenga posibilidad de representación (téngase en cuenta que una noticia no tiene un único tema, sino varios). Así, una noticia acerca de la incorporación de España al euro podrá encuadrarse de forma automática tanto en la sección de Nacional como en la de Economía.
- Proporcionar alimentación al mecanismo de gestión de la personalización dinámica. La personalización dinámica está basada en la detección automática de noticias que previsiblemente resulten interesantes al lector debido a su relación con otras noticias por las que ha mostrado interés previamente. Los temas son los mecanismos que permiten establecer esas relaciones entre noticias. Cuando el sistema detecta que un lector ha estado interesado en una noticia, el mecanismo de detección automática de preferencias anota los temas de esa noticia con el motivo de añadirlos a la lista dinámica de temas de interés del lector.
- Elaborar la bibliografía electrónica de cada noticia (al final de la misma o en torno a ella). A la hora de publicar una noticia es posible incluir referencias a otros documentos con el fin de permitir al lector profundizar contenidos. Esta bibliografía puede hacer referencias a tres categorías distintas de noticias:
- Otras noticias del mismo periódico, lo cual permite al lector hilvanar contenidos relacionados entre sí.
- Otras noticias almacenadas en la base de datos y accedidas por medio del servicio de hemeroteca digital, lo cual permite profundizar sobre los contenidos y elaborar las líneas de acontecimientos relacionados con la noticia.
- Otras noticias publicadas en otros periódicos, lo cual permite contrastar en otros medios la información conseguida.
Índice
Un periódico está formado por noticias agrupadas por secciones. Cuando el número de secciones que ofrece un periódico es razonable y el número de noticias por sección es relativamente grande, la simple enumeración de titulares con enlaces a las noticias una detrás de otro supone una gran cantidad de información que puede resultar inmanejable si no se proporciona al lector de los mecanismos adecuados. Los índices de nuestro periódico incorporan rutinas de plegado de forma que es posible compactar o expandir la información de cada sección o subsección haciendo visible al lector la información que desea consultar en cada momento. Este índice permitirá además resaltar los titulares de aquellas noticias que el sistema detecte como de mayor relevancia para el lector frente a las noticias que no sean consideradas como importantes.
Noticias
Pero si bien la primera imagen que recibe un lector acerca de su periódico no es otra cosa que su índice, lo cierto es que la información final, las noticias, son los elementos que finalmente siempre busca el lector. Lo anterior, los índices, no son más que simples cruces de caminos para llegar a la información de la noticia redactada por el periodista, si bien es cierto que también las noticias también pueden estar relacionadas entre sí a través del hipertexto permitiendo una navegación temática sin índices. Las noticias del periódico son ficheros escritos en un lenguaje de marcado basado en XML llamado JML (inicialmente, en nuestro prototipo el lenguaje de marcado de las noticias en HTML) que se conservan publicados durante un periodo de tiempo configurable (una semana, una quincena ...). Al igual que las noticias publicadas en la red por los periódicos electrónicos actuales, las noticias de nuestro prototipo pretenden incluir imágenes ilustrativas, publicidad (personalizada, aunque ficticia en un primer momento) y una bibliografía electrónica generada tanto manual como automáticamente y que intente mejorar la que ya existe en algunos diarios como Cinco Días.
Hemeroteca digital
Las noticias que han adquirido cierta antigüedad desde que fueron publicadas son eliminadas del servidor cuando se considera que han perdido interés para el público general. Sin embargo, siempre es posible extraer una versión de esa noticia accediendo directamente a la base de datos donde se almacena. El hecho de abrir la posibilidad de acceder a noticias que han dejado de ser publicadas y de realizar investigaciones en el periódico mediante búsquedas dirigidas por temas otorga al periódico electrónico un valor añadido de importancia tanto o más considerable en la medida en la que los contenidos de esa hemeroteca digital aumenten a lo largo del tiempo. Sin embargo, el acceso a esta base de datos es un proceso que requiere bastante capacidad de procesamiento y que sólo se puede realizar en el servidor (que es donde residen los datos). Nuestra solución para este problema consiste en la implementación de un programa CGI de búsqueda en la base de datos por distintos criterios combinables entre sí (temas, autores, fechas, secciones, lugares, ...).
Encuadernador digital
El encuadernador digital es el encargado de reunir los componentes del periódico que deben formar parte de la edición personalizada de cada lector y realizar su entrega conjunta al cliente. Básicamente se puede considerar a este servicio como un seleccionador de los fascículos que deben formar parte del periódico personalizado. Al contrario de los periódicos digitales actuales, que publican una serie de secciones separadas e interrelacionadas entre sí (los de edición impresa simplemente incluyen una edición completa de todas las secciones repartidas de forma consecutiva por no pocos hectogramos de papel), el encuadernador proporciona el periódico al lector en un único documento en el que sólo se incluyen las secciones que le interesan, de forma que este puede ser visualizado de un vistazo (usando las rutinas de plegado y desplegado) sin necesidad de estar permanentemente conectado a la red. La selección de aquellas secciones a las que está suscrito el lector (y por ende la no inclusión de las secciones a las que no está suscrito) permite que ese único documento no tenga un tamaño extraordinariamente grande como sí lo tendría un periódico que incluyera todas las secciones. Además, el encuadernador digital tiene en cuenta la especificación de un intervalo de fechas, de forma que es posible, por ejemplo, admitir y servir solicitudes del periódico personalizado de los últimos N días o entre dos fechas dadas.
Agente de personalización
La personalización de un periódico electrónico determina no sólo la forma en la que el lector visualice las noticias que lea, sino también la selección de las noticias que se entregan al lector en función de sus preferencias. Se distingue, por tanto entre una personalización de presentación y una personalización de contenidos.
La personalización de presentación afecta no sólo a los colores de los componentes de las noticias, al tipo y tamaño de letra o la disposición de esos elementos a lo largo y ancho de la pantalla, sino también al grado de resaltación con el que unas noticias aparecen destacadas respecto de otras o también a la forma en la que los titulares de algunas noticias son capaces de mostrar información adicional sobre su contenido (añadiendo una entradilla desplegable, por ejemplo). Para personalizar la presentación de las noticias se utilizan uso de hojas de estilo personalizadas.
La personalización de contenidos o proceso de cribación de noticias comprende una labor que se realiza conjuntamente en el servidor y en el cliente (con un esfuerzo por encaminar la mayor parte posible de esa labor desde el primero hasta el segundo). Con el fin de estimar el grado de interés que un lector pueda tener sobre determinada noticia, se han tenido en cuenta dos formas distintas en las que un lector pueda especificar las preferencias sobre los contenidos que puedan ser interesantes para él.
- Personalización estática: Consiste en la especificación explícita por parte del lector acerca de cuales son los temas que le interesan. En este tipo de especificación es posible decir que le interesan las noticias de determinadas secciones que traten de ciertos temas, especificar que le aparezcan resaltados los artículos de sus periodistas favoritos, o que simplemente no desea recibir determinadas secciones que nunca lee. La personalización estática permite al usuario, mediante el relleno de un formulario, una especificación precisa y controlada acerca de sus propios intereses. Sin embargo, esta especificación puede convertirse en una labor tediosa y que con el paso del tiempo acaba por dejar de ser usada ya que requiere la intervención explícita del lector y el uso de formularios de no poca complejidad.
- Personalización dinámica: Consiste en la detección automática de los intereses de un lector basándose en su comportamiento a la hora de leer el periódico con el fin de poder predecir en un futuro cercano el grado de interés que el lector pueda tener en las noticias del periódico. Este tipo de personalización tiene lugar de forma ágil para el usuario. Dado que este tipo de personalización está centrada en la captación de los intereses temporales del lector, se aplican sobre este tipo de preferencias algoritmos de envejecimiento que reflejen la pérdida de interés del lector sobre las noticias ya acontecidas. Téngase en cuenta que estos algoritmos de envejecimiento no se aplican en la personalización estática.
- Intereses de grupo o de comunidades virtuales: Aunque cada lector es completamente diferente, lo cierto es que es posible encontrar grupos de lectores con un conjunto de intereses comunes. Mediante una comparación de las personalizaciones estática y dinámica es posible reconocer estos grupos de personas y permitirles ponerse en contacto de forma que puedan intercambiar opiniones, comentarios, e intereses. El reconocimiento de estos grupos de personas permite realizar estimaciones sobre el interés medio que sobre una noticia pueda tener esa comunidad de forma que ese grado de interés pueda ser tenido en cuenta en la elaboración del periódico personalizado de cada uno de sus miembros. Así, cada uno de ellos no sólo verá resaltadas las noticias que le interesan, sino también aquellas cuyo grado de interés para el grupo al que pertenece haya sido catalogado como aceptable. La creación de foros de discusión sobre determinados temas o el intercambio de direcciones de correo electrónico de personas con intereses afines puede ser un valor añadido de gran importancia para el periódico electrónico del futuro, pues facilita que los lectores puedan encontrar gente con intereses afines.
- Finalmente, el periódico siempre puede estar interesado en mostrar determinados contenidos (considerados como importantes para la redacción) independientemente de si esos contenidos resultan o no seleccionados en el proceso de personalización. Por ejemplo, un periódico puede estar interesado en que se muestre al usuario lector siempre su noticia de portada o la editorial de su director. Este tipo de noticias, consideradas como de interés editorial permiten que el usuario pueda ser consciente de eventos importantes que afectan al conjunto de la sociedad. Tanto el interés editorial como el interés de las comunidades virtuales impiden el aislamiento cultural al que podría acarrear un periódico completamente personalizado de forma individual.
Parece evidente que una noticia debe aparecer tanto o más resaltada cuanto más grado de interés haya mostrado el lector sobre los temas de esa noticia (lo mismo sería aplicable al nivel de párrafo dentro de una noticia). Cuando el titular de una noticia no resulta seleccionado porque ninguno de sus temas es considerado de interés para el lector, pero esa noticia forma parte de una sección a la que está suscrito, el titular de esa noticia (el titular junto con una posible entradilla más un enlace para profundizar sobre el tema) es incluido en el periódico pero la noticia no aparece como resaltada. Sólo cuando el lector decida desplegar completamente esa sección y haya cuando menos contemplado los titulares de las noticias que le aparecen resaltadas, verá la referencia a esa noticia (junto con su posible entradilla desplegable). Esto se podrá realizar sin interactuar con el servidor de forma que se minimicen las transacciones entre el cliente y el servidor. Finalmente, aquellas secciones a las que no esté suscrito el lector no serán incluidas en la edición personalizada y por lo tanto sus noticias no se mostrarán al lector (salvo aquellas noticias que puedan pertenecer a otras secciones en las que el lector sí está suscrito).
Agradecimientos
El trabajo en el que se basa este documento ha sido parcialmente financiado por el proyecto TEL97-0788 de la CICYT. Queremos agradecer las aportaciones de nuestros compañeros Peter T. Breuer, Pilar Diezhandino, Tony Hernández, Natividad Martínez, Tomás Nogales, A. Rodríguez de las Heras y Luis Sánchez de la Universidad Carlos III de Madrid. Agradecemos también la ayuda prestada por El PAIS Digital y Fundesco.
Referencias
- Tim Bray, Jean Paoli, and C. M. Sperberg-McQueen (eds): XML: Extensible Markup Language (XML) 1.0 W3C Recommendation, 10 Febrero 1998. http://www.w3.org/TR/REC-xml
- ``Information Processing - Text and Office Systems - Standard Generalized Markup Language (SGML)'' ISO 8879:1986, First edition. Geneva, 15 Octubre 1986.
- Bert Bos, Håkon Wium Lie, Chris Lilley, Ian Jacobs (eds): CSS: Cascading Style Sheets, level 2 W3C Proposed Recommendation, 24-Mar-1998. http://www.w3.org/TR/1998/PR-CSS2-19980324
- Dave Raggett, Arnaud Le Hors, Ian Jacobs (eds): HTML 4.0 Specification W3C Recommendation, 18 Diciembre 1997. http://www.w3.org/TR/REC-html40-971218
- Lauren Wood, Jared Sorensen (eds): DOM: Document Object Model Specification, W3C Working Draft, 18 Marzo 1998. http://www.w3.org/TR/WD-DOM-19980318
- Richard Light. Presenting XML Sams Net, Indianapolis 1997. ISBN 1575213346
- ed. Dan Connolly. XML: Principles, Tools and Techniques Sebastopol, CA: O'Reilly, 1997 (World Wide Web journal; 2-4).
- LT XML Language Technology Group, Human Communication Research Centre, University of Edinburgh. http://www.ltg.ed.ac.uk
- ADEPT·Editor: Authoring Software for Knowledge Capture http://www.arbortext.com/editor.html
- MySQL T.c.X. DataKonsultAB http://ftp.sunet.se/pub/unix/databases/relational/mysql/index.html
- Krishna Bharat, Tomonari Kamba, Michael Albers Personalized, interactive news on the Web Multimedia Systems 6: 349-358 (1998)
- El Digital de Telepolis http://www.telepolis.es
- Titulares.com http://www.titulares.com
- Webreference.com http://www.webreference.com
-
Vicente Luque Centeno, Carmen Fernández Panadero,
 vlc [at] it [dot] uc3m.es mcfp [at] it [dot] uc3m.es
vlc [at] it [dot] uc3m.es mcfp [at] it [dot] uc3m.es
Carlos Delgado Kloos, Andrés Marín López,
cdk [at] it [dot] uc3m.es amarin [at] it [dot] uc3m.es
Carlos García Rubio
cgr [at] it [dot] uc3m.es
Área Ingeniería Telemática
Dept. Tecnologías de las Comunicaciones
Universidad Carlos III de Madrid
http://www.it.uc3m.es/~per