
 R. Castro y D. López
R. Castro y D. López
Resumen
PAPI es un sistema que permite el control de acceso a recursos restringidos en Internet, y surge como alternativa al problemático control de acceso basado en la dirección IP origen de la petición. El sistema se divide en un módulo de autenticación y otro de control de acceso. El mecanismo de autenticación se ha diseñado para ser lo más flexible posible, de tal forma que cada organización utilice su propio esquema de autenticación y permita mantener la privacidad de los datos de sus usuarios. Por otro lado, el esquema de control de acceso es transparente para el usuario, compatible con la mayoría de navegadores y no requiere ningún tipo de hardware o software adicional.
Palabras clave: PAPI, autorización, autenticación, clave, cookie, control de acceso
Summary
PAPI is a system for providing access control to restricted information resources across the Internet, and for solving problems derived from the use of access control methods based on IP source address. The system consists of two independent elements: the authentication server (AS) and the point of access (PoA). This structure makes the final system much more flexible and able to be integrated to different environments.
The authentication mechanisms are designed to be as flexible as possible, allowing each organization to use its own authentication schema, keeping user privacy, and offering information providers data enough for statistics. Moreover, access control mechanisms are transparent to the user and compatible with the most commonly employed Web browsers, i.e., Netscape/MSIE/Lynx, and any operating system.
Keywords: PAPI, authentication, authorization, key, cookie, access control
1.- Introducción
En los últimos años, el acceso a recursos restringidos dentro de Internet (bibliotecas, publicaciones, bases de datos específicas, etc.) se ha hecho cada vez más común. En la inmensa mayoría de los casos, se ha utilizado como método de control de acceso filtros sobre la dirección IP origen de la consulta, demostrándose claramente ineficiente en muchos casos.
Este es un problema que afecta a varias organizaciones conectadas a RedIRIS a la hora de acceder a recursos restringidos en Internet. En el año 2000, RedIRIS organizó una reunión a la que asistieron representantes, tanto de consorcios de bibliotecas localizados dentro de la red de I+D, como de empresas proveedoras de información por Internet. En esta reunión se trató la problemática antes descrita, y RedIRIS presentó una primera solución al problema, un sistema de control de acceso alternativo que solucionara el problema, y se adaptara a las necesidades de organizaciones con un gran número de usuarios. A la vez éste sistema debía ser: lo más transparente posible, compatible con los navegadores y servidores web más comunes, y que no necesitara de la instalación de software o hardware adicional. Una de las cosas más importantes que salió de esta reunión fue una lista de requisitos que deberían cumplir una solución al problema. Esta lista se detalla en la tabla que aparece a continuación.
La solución que se presentó en esta primera reunión tenía el nombre de PAPI (Puntos de Acceso a Proveedores de Información), y aunque el modelo era exactamente igual que el actual, su implementación se basaba en la utilización de certificados. Esta primera implementación tuvo sus problemas (que se comentarán en el punto 2) y evolucionó a la implementación basada en cookies que más adelante se describe.
En el punto 2 del artículo se realizará una comparativa de tecnologías, para más adelante, en los puntos 3, 4 y 5 explicar el modelo y su actual implementación y finalizar mostrando el estado actual del sistema, así como las líneas futuras de trabajo.

2.- Diferentes tecnologías
A continuación se detallan las soluciones frente a la problemática del control de acceso a recursos restringidos en Internet.
2.1.- Filtrado por IP origen
La mayoría de los proveedores de información en España utilizan como sistema de control de acceso filtros basados en la IP origen de las consultas que llegan a sus servidores. En general, cuando una organización contrata los servicios de uno de estos proveedores, debe de proporcionar el rango de direcciones IP de esa organización, lo que garantiza al proveedor de información que sólo usuarios autorizados accederán a su información. En general este sistema funciona, pero existen varios casos en los que falla:
2.2.- Login y Password
En esta solución, cada vez que un usuario accede aun servicio, debe dar al sistema un código de usuario y una clave asociada. Esto presenta los siguientes problemas:
2.3.- Certificados
Este sistema de control de acceso se basa en la recepción por parte del usuario de un certificado personal de navegador con el que se puede identificar a la hora de acceder a un recurso vía web.
3.- Arquitectura del sistema PAPI
El sistema, como puede verse en la figura 1, consta de dos partes: el servidor de autenticación (AS) y el punto de acceso (PoA). Ambos elementos son independientes, no existiendo ninguna restricción respecto a número o localización de cualquiera de ellos. Gracias a esto el sistema final resulta mucho más flexible y configurable.
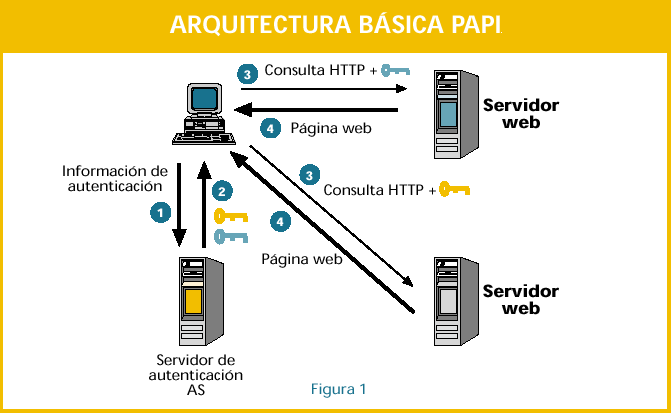
El AS se encarga de realizar la autenticación al usuario. Una vez que ha comprobado que el usuario es quien dice ser, el AS comprueba a qué recursos tiene acceso el usuario que se acaba de autenticar.
Para cada uno de estos recursos, el AS le entrega al usuario una clave temporal encriptada (el periodo de validez es configurable) que le permitirá más adelante acceder al recurso en cuestión. Esta clave se puede asemejar una llave con un tiempo de validez. Al final de la autenticación, el usuario tendrá en su poder una llave para cada uno de los recursos para los que él está autorizado a entrar.
El PoA se encarga de realizar el control de acceso al recurso restringido. Cuando el usuario realiza una consulta a un recurso protegido por un PoA, éste comprueba si el usuario posee una clave válida y si ésta ha sido emitida por un AS válido. Si es así, le deja pasar y cada cierto tiempo le entrega al usuario una nueva clave para seguir entrando. Este procedimiento de refresco de clave sirve para evitar que dos usuarios entren con la misma clave, es decir, evita la copia de clave entre equipos. En realidad los PoAs son como cerraduras, y sólo aquellos usuarios que poseen la llave correcta pueden pasar.
Una vez que la clave temporal ha vencido, el usuario tiene que volver a autenticarse para poder conseguir nuevas claves. La utilización de claves temporales permite el no tener que gestionar listas de revocación, como ocurre por ejemplo en el caso de certificados permanentes.
3.1.- Ventajes de utilizar este modelo
También admite otros modelos, como que una misma organización tenga el servidor de autenticación y los puntos de acceso, por ejemplo para proteger distintos recursos internos de la organización en función: del tipo de usuario que accede, el departamento al que pertenece, etc.
4.- El protocolo del sistema PAPI
Para la implementación del sistema PAPI en un primer momento se optó por utilizar certificados de usuario, pero por los problemas descritos anteriormente, se desechó ese camino y se optó por un elemento que resulta mucho más transparente y fácil de utilizar para los usuarios, las "cookies". Esta
tecnología eliminaba una parte de los problemas, pero introducía uno más técnico. El problema, a grandes rasgos, resulta en que sólo el servidor que da las cookies, puede después recibirlas. Esta descripción del problema no es exacta ya que en realidad lo que debe ser igual es el dominio, pero para este caso sirve. Para solucionar este problema se forzó a que el sistema hiciera eso, es decir, que fueran los PoAs los que entregaban las claves temporales que después ellos mismos van a utilizar.
El protocolo que emplea el sistema PAPI consta de dos fases: autenticación y control de acceso. La fase de autenticación comienza cada vez que el usuario accede al servidor de autenticación (AS) para conseguir las claves temporales. Una vez conseguidas, no debería volver a esta fase mientras las claves son válidas. Sólo en ciertos casos el usuario tiene que volver a autenticarse de manera prematura:
1.- Cuando las claves temporales son borradas del navegador (en la implementación actual, cuando las cookies son borradas del fichero de cookies del navegador).
2.- Cuando las claves temporales se corrompen.
3.- Cuando las claves temporales se copian a otro equipo y el sistema detecta colisión entre dos usuarios utilizando las mismas claves.
4.- Cuando la clave de encriptación principal (K1), que se describe más adelante, se cambia porque ha sido comprometida.
4.1.- La fase de autenticación
Esta fase comienza, como puede verse en la figura 2, cuando el usuario se autentica y finaliza cuando las cookies temporales que le permiten pasar por los diferentes PoAs están almacenadas en el navegador.
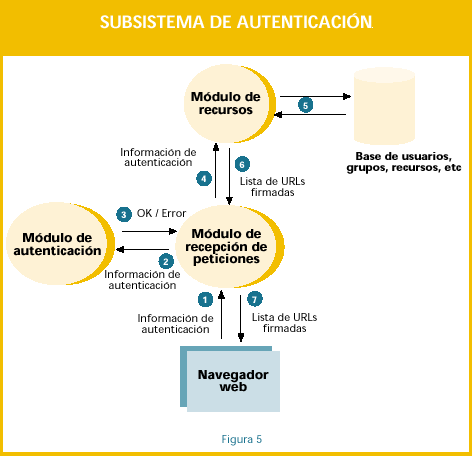
1.- El usuario se conecta con el navegador al servidor de autenticación y le facilita la información que fuera necesaria para su autenticación.
2.- Esta información es analizada por el módulo de autenticación que la organización haya considerado oportuno, o que haya desarrollado.
3.- Si la autenticación es válida, el servidor consulta a qué recursos tiene acceso el usuario y durante cuanto tiempo. Esto puede tener relación con el tipo de usuario que es, el departamento al que pertenece, desde dónde está realizando la autenticación, etc. Una vez obtenida la lista de recursos a los cuales puede acceder este usuario, el AS genera una página web de respuesta con una serie de URLs firmadas (no pueden ser cambiadas). Las URLs firmados tienen los siguiente campos:
- a. AS: Nombre del servidor de autenticación
- b. ACTION: Acción a llevar a cabo:
- i. LOGIN: Petición de nuevas claves
- ii. TEST: Comprobación de acceso a ese PoA
- iii. LOGOUT: Desconexión, es decir, borrado de las claves de acceso
- c. DATA: Información sobre la conexión:
- i. Fecha de creación de la URL
- ii. Fecha de expiración para el acceso
- iii. Código del usuario
4.- El navegador recibe esta página y resuelve las URLs antes descritas de una manera completamente transparente para el usuario, ya que cada una de ellas se corresponde con la carga de un gráfico. Cada URL se corresponde con un PoA del cual se quiere obtener su acceso.
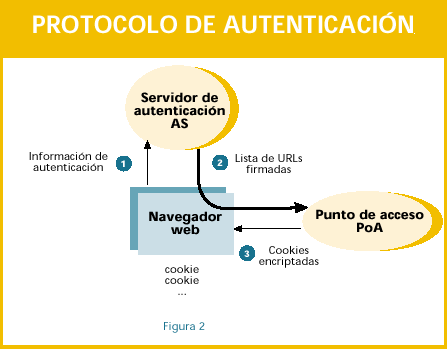
5.- Cuando un PoA recibe una URL firmada, éste comprueba que haya sido generada por un AS válido y sus datos no hayan sido cambiados.
6.- Si es así, genera un par de cookies (Hcook y Lcook) encriptadas con unas claves simétricas propias y las devuelve al navegador para que las guarde. La estructura de las cookies: d. Hcook: i. Fecha de expiración del acceso ii. Código del usuario iii. AS donde se autenticó iv. Servidor para la cual es válida la cookie.
v. Ruta para la cual es válida la cookie vi. CRC aleatorio de seguridad que se cambia cada vez que expira Lcook e. Lcook: i. Fecha de creación ii. Servidor para el cual es válida la cookie iii. Ruta para la cual es válida la cookie.
A partir de este momento el usuario tendrá acceso a los recursos para los que ha obtenido las cookies correspondientes.
4.2.- La fase de control de acceso
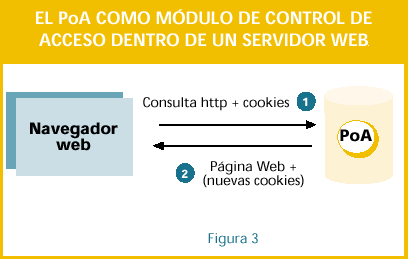 Consulta http + cookies
En esta fase, ver la figura 3, el
usuario intenta acceder a un recurso
que está controlado por un PoA.
Consulta http + cookies
En esta fase, ver la figura 3, el
usuario intenta acceder a un recurso
que está controlado por un PoA.
Página Web + (nuevas cookies) 1.- Al realizar la consulta, el navegador envía automática- mente las cookies (Lcook y Hcook) relativas a ese PoA.
Lcook también lleva un tiempo de expiración corto que conlleva la renovación de Hcook. Con ello se evita la copia de Hcook en varios equipos 2.- Cuando el PoA recibe la consulta, extrae las cookies y comprueba la validez de la cookie Lcook. Si es válida deja pasar la consulta.
3.- Si no es válida o ha expirado comprueba Hcook: a) Comprueba la fecha de expiración.
b) Comprueba si este Hcook es el mismo que está registrado en la base local de Hcooks. c) Comprueba si existe algún filtro para este usuario.
4.- Si es válida, genera nuevas Hcook y Lcook, registra la nueva Hcook como válida en la base local y deja pasar la consulta.
La utilización de dos cookies en vez de una sirve para dar una mayor eficacia al sistema, sin perder seguridad. La clave Lcook lleva un sistema de encriptación más ligero, lo que permite una mayor rapidez en su chequeo. La clave Hcook lleva más información y una clave de encriptación más fuerte y más pesada a la hora de ser comprobada. Esta comprobación se realiza cada más tiempo, con lo cual se consigue no perder eficacia, aunque se sigue manteniendo la robustez de una buena encriptación.
4.3.- La funcionalidad GPoA
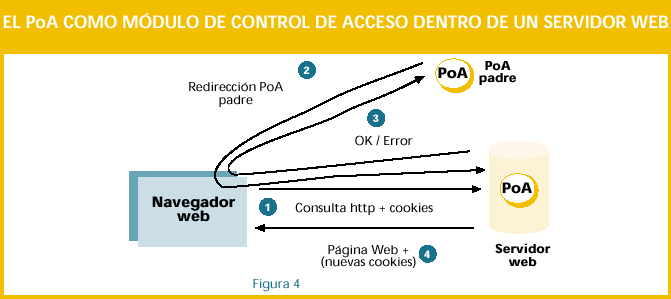
A los puntos de acceso (PoA) se les ha dotado de una funcionalidad que les permite agrupar a varios PoAs bajo su misma política (GPoA). Cuando a un PoA se le asocia otro PoA como padre (GPoA) lo que ocurre es que las decisiones sobre si una petición pasa o no, se delegan en el PoA padre. El mayor beneficio de este esquema es que con una sola cookie (del PoA padre) se da acceso a varios PoAs hijos. El funcionamiento, véase la figura 4, es el siguiente: 1. Llega una consulta 2. Se comprueban las cookies de acceso.
3. En caso de que no tenga cookies o estén ambas expiradas, se redirige una consulta de acceso al PoA padre (GPoA).
4. El GPoA recibe la petición del PoA hijo. 5. Si el usuario tiene las cookies de acceso necesarias para el GPoA, se le responde OK al PoA hijo.
6. Si no las tiene, se responde con ERROR al PoA hijo. Una vez que una petición ha sido validada por un PoA padre, el PoA hijo generará nuevas cookies y todo exactamente igual que si hubiera sido validada por un AS.
5.- Implementación actual
La última distribución de PAPI está disponible en http://www.rediris.es/app/papi/dist/. La implementación actual incluye un servidor de autenticación y un punto de acceso.
5.1.- Servidor de autenticación
Está implementado en Perl con soporte para varios métodos de autenticación: LDAP, POP-3, y sobre una base de datos local. El servidor de autenticación es un CGI que puede instalarse sobre cualquier servidor web, y es fácilmente ampliable con nuevos métodos de autenticación. Además tiene un sistema de plantillas que permite configurar el aspecto de sus páginas web. Como se puede observar en la figura 5, un servidor de autenticación está compuesto internamente por diferentes módulos:
5.2.- Punto de acceso
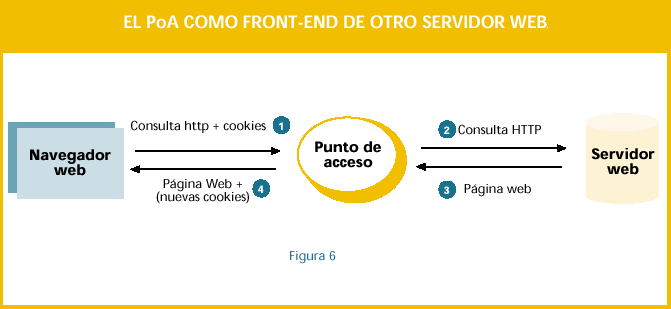
 La implementación actual
está basada en mod_perl
para servidores web
Apache. Aún así existe un
modo de funcionamiento,
que ya está siendo
utilizado, tipo Front-end,
de forma que el control de
acceso se sigue realizando,
pero detrás se puede
poner cualquier tipo de
servidor web. Como se
muestra en la figura 6, se
pone delante del servidor
web (bien en el proveedor
de información, bien en la
organización cliente), una
máquina con servidor web
Apache y el Punto de
Acceso instalado. Cuando
se realiza una consulta
web, se fuerza a que pase por el Apache. En éste se realiza el control de acceso, y si todo está
correcto, él mismo realiza la petición, devolviendo posteriormente el resultado al usuario. Es un modo
de funcionamiento equivalente a proxy-inverso.
La implementación actual
está basada en mod_perl
para servidores web
Apache. Aún así existe un
modo de funcionamiento,
que ya está siendo
utilizado, tipo Front-end,
de forma que el control de
acceso se sigue realizando,
pero detrás se puede
poner cualquier tipo de
servidor web. Como se
muestra en la figura 6, se
pone delante del servidor
web (bien en el proveedor
de información, bien en la
organización cliente), una
máquina con servidor web
Apache y el Punto de
Acceso instalado. Cuando
se realiza una consulta
web, se fuerza a que pase por el Apache. En éste se realiza el control de acceso, y si todo está
correcto, él mismo realiza la petición, devolviendo posteriormente el resultado al usuario. Es un modo
de funcionamiento equivalente a proxy-inverso.
La parte de encriptación de cookies se realiza utilizando el protocolo de encriptación simétrica EAS.
6.- Estado actual
Toda la información referente a PAPI se encuentra en http://www.rediris.es/app/papi. PAPI se está utilizando actualmente como sistema de control de acceso a los recursos web de RedIRIS. Además, dos consorcios de bibliotecas están usando PAPI como método de control de acceso a sus recursos digitales.
En la actualidad PAPI se encuentra en una fase de evaluación llevada a cabo por diversas redes de investigación europeas, tanto como punto de autenticación único de acceso a recursos digitales, como sistema de intercambio de contenidos a nivel interinstitucional. Así mismo, se están probando nuevos métodos de autenticación dentro de PAPI. Como ejemplo, cabe destacar la red holandesa, que próximamente va a comenzar un piloto que será utilizado en diversas universidades de enseñanza a distancia.
En la última reunión mantenida con las organizaciones que están siendo (o tienen intención de serlo próximamente) piloto en el uso de este sistema, se ha llegado a acuerdos en los diferentes modos de probar PAPI. Hay organizaciones que optan por ser ellos los que instalen y gestionen tanto el AS como los PoAs, y otras, que prefieren que sea RedIRIS quien gestione su AS y sus PoAs, para después llevarse el sistema a sus instalaciones.
7.- Conclusiones y próximas tareas
En este artículo se describe un sistema que partió de la necesidad de resolver el problema existente entre cliente y proveedores de información a la hora de controlar el acceso a usuarios. La arquitectura y protocolos de este sistema se basan en resolver este problema, consiguiendo una solución práctica y fácil, que no requiera la instalación de software adicional, y que interfiera lo menos posible en los servidores y herramientas de consulta desarrolladas por los proveedores.
En el desarrollo de este sistema se quiere trabajar muy estrechamente con usuarios y proveedores y serán ellos los que marquen las nuevas necesidades y tendencias en su evolución. Por ello, se seguirán convocando reuniones con ambas partes, y teniendo en cuenta sus sugerencias se incorporarán mejoras a PAPI.
7.1.- Próximos resultados
1. Implementación de PAPI para otras plataformas: Está a punto de salir una versión que funcionará en Microsoft Internet Information Server. En esta implementación se ha trabajado mucho para que la instalación y configuración resulten muy sencillas.
2. Nueva API de desarrollo. Aprovechando la necesidad de portar PAPI a más plataformas, se ha desarrollado una librería para C, con la que se pretende facilitar futuros desarrollos.
3. Reautenticación en transacciones críticas. Esta funcionalidad permitiría la reautenticación del usuario que está realizando la transacción en el momento de hacerla. Se puede pensar en una zona de un web que esté restringida a usuarios del centro, y en un momento dado en el que se dé una transacción crítica, el sistema compruebe si la persona que está utilizando las claves temporales es realmente quien dice ser.
4. Flexibilidad en el control de acceso. Ahora mismo es posible agrupar puntos de acceso bajo uno que decide si se permite el acceso o no, pero se ha visto la necesidad de incluir condiciones de acceso en los PoAs un poco más elaboradas, en las cuales (previo acuerdo entre AS y PoA), se pudieran utilizar otros criterios de filtrado (Ej.: ¿pertenece a este departamento?).
En cuanto a política de apoyo a la integración de esta tecnología en las organizaciones, se ofrecerá una modalidad, en la cual, RedIRIS ofrecerá sus infraestructuras como plataforma para el arranque de sistemas PAPI, que posteriormente serán migrados a las organizaciones correspondientes.
En todas estas actuaciones y líneas de trabajo tendrán gran importancia tecnologías afines que se están comenzando a desarrollar y con las cuales PAPI será compatible.
Rodrigo Castro
( rodrigo [dot] castro [at] rediris.es)
rodrigo [dot] castro [at] rediris.es)
Equipo de seguridad IRIS-CERT
Diego López
( diego [dot] lopez [at] rediris.es)
Coordinador de Aplicaciones