
 Juan Antonio Martínez
Juan Antonio Martínez
Resumen
El objetivo de la presente ponencia es llegar a un modelo que permita evaluar la calidad de servicio que ofrece una red de campus. Queremos llegar a un modelo matemático que aplicado a una red cualquiera nos proporcione su valor de disponibilidad. El entorno en estudio es una red de unos 5000 puntos con gestión SNMP en los activos de red.
El modelo no adopta los parámetros clásicos de monitorización de QOS como puedan ser retardo o jitter. En vez de eso, valoramos la calidad ofrecida en función de los índices de disponibilidad tanto de la red como de los servicios.
Conseguido el modelo matemático, expondremos el estado de implantación en la red de la Universitat Autònoma de Barcelona y los requisitos software y hardware necesarios para su implantación en otras redes que deseen aplicar un sistema similar.
Palabras clave: monitorización de red, monitorización de servicios, calidad de servicio, disponibilidad, gestión de red
Summary
This paper discusses a model for evaluating the Quality of Service of a Campus-Wide network. The main goal is to achieve a mathematical model that can be applied to any network, providing its availability. The network where it will be tested has more than 5000 nodes with SNMP managed network devices.
The model discards the classical approach to QOS that considers parameters such as delay or jitter. Instead, we evaluate quality as a function of the availability indexes for either the services or the network itself.
Once the model is described, we will explain how it has been implemented at the Universitat Autònoma de Barcelona Campus network and the requirements software and hardware to install such a system in other networks.
Keywords: network monitoring, service monitoring, quality of service (QOS), availability evaluation, management.
1.- Introducción
El presente artículo detalla el proceso seguido para la obtención de un modelo de disponibilidad y calidad de servicio de una red. El objetivo fundamental era ver si nuestra red se acercaba a la disponibilidad ideal de `5 nueves'. Una vez conseguido, buscaríamos ver la calidad de los servicios de alto nivel.
2.- Parámetros para evaluar la QoS de una red genérica
Toda la bibliografía referente a calidad de servicio se basa en parámetros como la tasa de pérdidas de paquetes, el retardo y el jitter([1],[2]). Si bien estos parámetros son válidos para monitorizar enlaces WAN, creemos que no son adecuados para entornos de red local. Medidas experimentales sobre nuestra red demuestran que, en situaciones normales, las tasas de pérdidas de paquetes son despreciables y los retardos son bajos.
El uso de los parámetros antedichos presenta un problema adicional: requieren un entorno de medida distribuido. Esta problemática no está presente en los enlaces WAN, donde conseguir esos valores es relativamente simple([1],[2]). En cambio, en los entornos de red local, una solución de ese tipo es compleja para redes segmentadas, donde los valores de retardo, jitter y pérdidas son diferentes para cada segmento.
Algunas aproximaciones al problema utilizan SNMP como solución. Si bien SNMP es muy útil para determinar la accesibilidad, no lo es tanto para dar un nivel de respuesta. Nuestra experiencia nos demuestra que los tiempos de respuesta de los dispositivos de gestión vienen más condicionados por la lentitud de la gestión que por la propia red. Esto se comprueba fácilmente interrogando a una estación sin carga y a un equipo con gestión ubicados ambos en el mismo segmento ([6]).
Basarnos en una medida falseada para dar un modelo nos parecía poco aceptable. El coste de implantar un sistema simple basado en sondas para una red con algo más de 70 segmentos nos parecía impracticable. A partir de este punto buscamos un modelo más simple y a la vez más ajustado al entorno en estudio.
De todo lo dicho, sacamos la idea de que lo más adecuado era un modelo mixto. Parámetros como las pérdidas de paquetes y los tiempos de respuesta serían válidos para los enlaces WAN. Para la red interna, nos resulta más útil un valor numérico que indique su disponibilidad. Los servicios clásicamente más asociados a la red (correo electrónico, ftp, web,...) los analizaremos también en términos de disponibilidad.
3.- Modelo práctico para la evaluación de la disponibilidad de la red
3.1.- Requisitos del modelo
El modelo que buscamos debe:
- Ser válido para cualquier red, siempre y cuando sus elementos activos dispongan de gestión (SNMP).
- Proporcionar un valor numérico que corresponda a la disponibilidad en cualquier momento. Adicionalmente, generar un valor medio de la disponibilidad mensual.
La idea básica del modelo es evaluar la influencia de la caída de un equipo sobre el conjunto de la red. Para ello, lo que hacemos es determinar a cuantos usuarios afecta. Conocidos estos usuarios y los usuarios totales, podremos determinar la importancia relativa de la caída.
Si bien esta fue la aproximación inicial, creemos que un modelo tan lineal no se ajusta a la realidad. Dos elementos cuyo fallo afecte al mismo número de usuarios, pueden tener importancias relativas diferentes. Así, es diferente la pérdida de conectividad del segmento donde se ubica un servidor departamental, que la caída del router corporativo. Por ello, debemos introducir un coeficiente adicional que dé idea de la criticidad subjetiva.
Consideraciones prácticas demuestran imposible monitorizar absolutamente todos los dispositivos de red. Debemos llegar a una solución de compromiso. Monitorizar todos los dispositivos lleva a un valor más preciso pero es computacionalmente costoso y no siempre posible. Una monitorización de muy pocos dispositivos lleva a un valor erróneo de la disponibilidad.
3.2.- Implementación práctica
En nuestro caso concreto, la red se estructura en segmentos ethernet, con un conjunto de switch centrales y otros de segundo nivel. Estos switch de segundo nivel dan lugar a un conjunto de segmentos 10/100.
Aun cuando el tráfico pueda ser diferente en cada uno de los segmentos, en términos de disponibilidad la caída de un conmutador afecta a todos los segmentos que cuelgan de él. Por ello en nuestro análisis nos limitamos a monitorizar los conmutadores de primer y segundo nivel. Llegar hasta los últimos concentradores proporcionaría mayor granularidad, pero supondría pasar de monitorizar unos 10 elementos a más de 150.
Para la modelización matemática, sea Kc1 el número de usuarios a los que afecta la caída de dicho conmutador. Si dividimos este número por el total, obtenemos la importancia relativa kc1. Por otra parte, y a partir de nuestra experiencia definimos un valor de importancia subjetiva Kc2 donde 0 indica criticidad mínima y 10 criticidad máxima, que también pasamos a valor relativo. La siguiente tabla expresa lo dicho hasta el momento, aplicando el modelo a nuestra red.
|
Descripción |
Activo de red |
Dirección
IP |
Coef. |
Coef. Usuario |
Valor criticidad |
Valor criticidad |
Coef. global |
|
Router salida |
Gw |
158.109.0.3 |
2920 |
0,3333 |
7 |
0,0729 |
0,20312 |
|
Corebuilder |
CB |
158.109.0.26 |
2920 |
0,3333 |
9 |
0,0937 |
0,21354 |
|
Switch. SI |
si0swfo1+si0swfo2 |
158.109.2.233 |
187 |
0,0213 |
8 |
0,0833 |
0,05234 |
|
Ciencias norte |
c7p1sw1 |
158.109.8.236 |
357 |
0,0407 |
6 |
0,0625 |
0,05162 |
|
... |
|
|
|
|
|
|
|
A partir de los coeficientes kc1 y kc2 obtenemos un coeficiente global que es el que aplicaremos al modelo. Este coeficiente global es sencillamente la media aritmética de los valores anteriores, aunque puede optarse por otro tipo de ponderación si así se desea. Si llamamos a este nuevo coeficiente kd la disponibilidad instantánea queda como:

donde Kdi es cada uno de los coeficientes de disponibilidad y di un valor binario que indica si el activo en cuestión está disponible o no en el momento de la monitorización. Queda tan sólo evaluar la disponibilidad promedio. Aun cuando evaluamos otras posibilidades, como los filtros de mediana,finalmente optamos por una media aritmética. O sea,
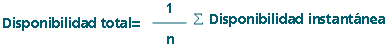
cosa que para el modelo de muestreo discreto también puede expresarse como:

fórmula que simplifica el cálculo ya que permite la evaluación de la disponibilidad a partir del último valor calculado, la media acumulada y el número de muestras hasta el momento.
3.3.- Consideraciones sobre la implementación práctica del modelo de disponibilidad
Para implementar el modelo anterior se ha hecho uso de un programa C que recoge los datos de los activos a monitorizar de un fichero de configuración.
Para calcular la disponibilidad instantánea, se considera que un elemento está activo si responde a una petición ICMP (ping). Para evitar posibles problemas en la gestión de los equipos, se lanzan varios `ping' y se esperan las respuestas. Con estos datos y los coeficientes calculados, puede determinarse la disponibilidad instantánea.
Este valor de disponibilidad se almacena en un fichero de texto, donde la última línea indica el número de muestras tomadas hasta el momento y la disponibilidad promediada. Gracias a estos dos valores, el cálculo de la nueva disponibilidad resulta simple con las fórmulas obtenidas en el apartado anterior.
4.- Modelo para la evaluación de la calidad de funcionamiento de los servicios
Nuestra primera idea fue hacer un sistema que nos diera simplemente el estado de los servicios que estaban operativos en los servidores corporativos. Así, en el mismo fichero de configuración que permitía la evaluación de la disponibilidad de red, se incluía otra sección con los servidores y servicios que debían verificarse.
Este modelo es fácilmente extensible. Si eliminamos los coeficientes de criticidad, resulta un sistema válido para evaluar la disponibilidad de un servicio concreto. La única diferencia radica en el cálculo de la disponibilidad instantánea, que en lugar de evaluarse mediante herramientas como ping, se hace mediante los programas de comprobación de funcionamiento del servicio que acabamos de comentar.
De cara a proporcionar un sistema aún más potente y flexible, pensamos en evaluar otros valores en los servicios. Por ejemplo, saber si el servidor de correo está consumiendo mucha CPU, memoria, etc.
Las posibilidades planteadas para un sistema de monitorización centralizado eran:
- Realizar procesos de monitorización remotos, mediante uso de rutinas de tipo remote shell (rsh).
- Realizar procesos de monitorización locales a cada máquina y exportar los resultados a una máquina central para su proceso.
La primera de las soluciones presenta problemas de seguridad en las máquinas para ejecutar ciertos procesos que pueden requerir acceso privilegiado. La segunda nos pareció buena, con el único inconveniente de disponer de un sistema para exportar los datos universalmente válido.
La solución de la exportación NFS hubiera sido válida, pero pensamos en un sistema más abierto. Idealmente y por tratarse de un sistema de gestión, pensamos que lo más deseable sería una solución basada en SNMP. Esta solución, no sólo sería la más abierta y estándar([3],[4],[5]) sino que además se integraría perfectamente con el software de gestión gráfica que utilizamos (MRTG).
4.1.- Detalle de la implementación
Con lo dicho hasta ahora se requiere un sistema en el que:
- Un conjunto de rutinas obtengan los datos que queremos monitorizar.
- Un demonio SNMP que se comunique con dichas rutinas y exporte los valores a la estación de gestión.
- Una MIB para acceder a dicha información([4],[6]). Disponer de las rutinas no supone un problema grave. De hecho, ya disponíamos de scripts de monitorización que obtenían los datos más relevantes de muchos de los servicios que nos interesaban.
Faltaba exportar dichos datos vía SNMP. El demonio snmp que se requiere para esto (clásicamente, snmpd) no funciona en este caso ya que no reconocería los valores que se le pidieran de nuestra mib-2 propietaria. El demonio modificado lo construimos a partir de una versión del ya existente en la Universidad de California-Davis ([7]).
Generamos un fichero en formato de definición de mib, y, lo integramos en el código fuente del demonio. El código generado es absolutamente portable.
Respecto al modo de operación, los procesos locales escriben los datos monitorizados a un fichero (data.snmp). Ante una consulta, el demonio obtiene los datos de dicho fichero. En nuestra implementación todas las variables son de sólo-lectura, ya que no nos planteamos la actuación activa hacia un servicio monitorizado con SNMP.
5.- Análisis global del sistema
A modo de resumen, el sistema consta de:
- Un conjunto de rutinas, escritas en lenguaje C, que verifican el correcto funcionamiento de los servicios básicos de red. En nuestro caso, los servicios son bootp, dhcp, dns, ftp, http, mail (pop, imap, smtp), radius y news.
- Un fichero de configuración que permite evaluar qué servicios quieren comprobarse y en qué máquinas funcionan. Este fichero contiene además los datos requeridos para el modelo de evaluación de la disponibilidad.
- Un sistema para evaluar el porcentaje de disponibilidad de la red.
- Una versión modificada del demonio snmp, que junto con la definición de la mib ([4],[6]) permite monitorizar los procesos en local e interrogarlos desde cualquier estación de gestión, presentando además integración con el MRTG.
Los beneficios más relevantes que se obtienen son:
- Sistema simple para comprobar el funcionamiento de todos los servicios críticos de red.
- Informe mensual del índice de conectividad interna y externa.
- Informe de la disponibilidad de servicios.
6.- Conclusiones
El modelo descrito es simple, fácil de implantar y da una idea numérica de la disponibilidad de la red y los servicios. Adicionalmente, es suficientemente versátil como para añadirle funcionalidades tales como la detección de problemas de red y la monitorización de servicios de más alto nivel.
7.- Referencias
Internet Service Performance: Data Analysis and Visualization. Consultado en: http://www.xiwt.org/documents/IPERF-paper2.pdf
- Matthews,W.; Cottrell, Les: PingER: Internet Performance Monitoring. INET'99 Proceedings (Poster nr.26)
- Mc.Ginnis, Evan; Perkins, David: Understanding SNMP MIBs. Prentice Hall 1996. ISBN: 0134377087
- Rose, Marshall T: Management Information Base for Network Management of TCP/IP-based Internets:MIB-II. RFC 1213
- Stallings, W.: SNMP, SNMPv2, SNMPv3, and RMON 1 and 2. Addison Wesley Longman, Inc. Dic. 98. ISBN: 0201485346
- Steinberg, Louis: Troubleshooting with SNMP & Analyzing MIBs. Mc.Graw-Hill. Jun.2000. ISBN:0072124857
- UCD-SNMP Project Home Page. Consultado en: http://ucd-snmp.ucdavis.edu.
Juan Antonio Martínez
 juanan [dot] martinez [at] uab.es
juanan [dot] martinez [at] uab.esServei d'Informàtica
UAB