
 Leandro
Navarro, Victor J. Sosa
Leandro
Navarro, Victor J. SosaEl éxito del Web entre los usuarios de la red ha producido un volumen de tráfico intratable, y que consume cualquier capacidad de comunicación. Las jerarquías de servidores proxy-caché ayudan a disminuir el número de veces que un mismo documento se importa aprovechando las peticiones de los usuarios. Se presenta estrategia complementaria a la caché que consiste en la distribución de contenidos web. Cuando un documento se publica, se distribuye hacia servidores biblioteca (servidores proxy web suscritos a ciertos temas de interés) en lugar de esperar a las peticiones. Se organiza una red de distribución de contenidos que minimiza el número de veces que cada documento circula por la red, y traslada esa distribución a horas de bajo tráfico, reduciendo la carga de pico de la red.
El servidor proxy de una organización responderá a las peticiones de los usuarios devolviendo objetos de la caché (alguien ya lo pidió), del almacén (se está subscrito a ese tema) o tendrá que ir a buscarlo al URL original. Por ejemplo, si la biblioteca de un departamento quiere suscribirse a cierta publicación en formato electrónico, este sistema permitiría que recibiera y ofreciera localmente los nuevos ejemplares poco después (o algo antes) de haberse hecho públicos, sin penalizar al primer usuario que decida acceder, ni generar tráfico de pico en ese instante.
Se presenta la problemática a solucionar mostrando las ventajas adicionales que aporta respecto a un proxy-cache. Se describen las herramientas desarrolladas: una utilidad para producir colecciones de páginas Web basado en la especificación mhtml del IETF [Palme 98] y dos herramientas cliente: un módulo para Apache y un cgi de consulta del contenido del almacén.
El estado de la Red
La Internet pensada en los 70 realiza la tarea de transportar documentos Web de forma cada vez más lenta e impredecible. Este efecto es resultado de una compleja combinación de fenómenos, entre ellos el crecimiento explosivo de la población de usuarios, el tráfico frecuente de documentos, y de la proliferación de contenidos de calidad y volumen muy diverso.
La calidad de servicio de la red es muy variable: la carga de tráfico agregado generado por tantos usuarios es, en cualquier momento o periodo del día, muy variable, caótico (auto-similar, fractal), con independencia de la capacidad de la red [Leland 94], [Crovella 95].
A esto hay que sumar la carga y los fallos de los servidores debido al gran número de peticiones simultáneas, particiones en la red, sobre todo en documentos lejanos.
Empeora aún más cuando una gran población tienen un interés común por un documento en el mismo momento, lo que colapsa al servidor y la vecindad de la red en se encuentra. Este fenómeno, el "flash-crow" [Nielsen 95], ocurre sobre todo en información de gran interés en cierto instante y que llega más rápido por Internet que por otro medio: resultados de competiciones, elecciones, imágenes de una misión espacial, etc.
Como resultado de los efectos anteriores, muchos recursos son inaccesibles para una gran cantidad de usuarios que ven frustradas las expectativas que tenían sobre la red.
Además, hay malas noticias, el web crece peor que otros servicios: los accesos apuntan a cualquier lugar de la red, a diferencia del correo, news, dns en que hay dos niveles: el cliente habla con su proxy, y los proxis hablan entre sí. Esta separación facilita el crecimiento ordenado: como si para leer un libro visitáramos al autor en lugar de la biblioteca.
Aprovechando Peticiones: Proxy-Caché
Una caché mantiene cerca de los clientes documentos que puedan ser solicitados de nuevo. Se suelen situar en tres lugares: caché en el cliente, integrada en el navegador; caché en los servidores, junto al servidor Web; y las cachés proxy, en una localidad intermedia y compartida por un grupo de usuarios relacionados (ej. misma intranet, empresa, región o país, etc.).
El principal uso del proxy es permitir el acceso Web desde dentro de una zona de seguridad tras un cortafuegos (firewall) [Luotonen 94]. El proxy es un servidor HTTP especial que suele correr en el cortafuegos y por tanto separa y media entre las peticiones internas y la Internet.
Los proxy caché puede trabajar de una manera aislada (sólo uno) o cooperar entre ellos (dos o más). Las estrategias de cooperación entre proxis varían según el uso de diferentes protocolos y las estrategias de comunicación. La siguiente tabla muestra los protocolos y estrategias de comunicación entre caché más importantes, con una descripción breve y algunos productos que los implementan.
|
Protocolo/Estrategia Descripción |
Implementado en |
| Internet Cache Protocol (ICP) | |
| Consulta entre cachés para saber si un objeto que se desea extraer del Web se encuentra entre ellas. ICP utiliza UDP y sufre de sus problemas de seguridad y fiabilidad. Se calcula una estimación de la congestión y disponibilidad de la red por los paquetes ICP que se pierden. Esta medida, junto con el tiempo de ida y vuelta de los mensajes permite el balanceo de carga entre cachés. ICP no transporta información acerca de las cabeceras HTTP asociadas con un objeto. Las cabeceras HTTP pueden incluir controles de acceso y directivas al caché, ya que los cachés preguntan por objetos para posteriormente extraerlos utilizando HTTP. Se pueden presentar falsos hits en el caché (p. ej. objetos que están en un caché pero no se permite acceso desde cachés hermanas). | Harvest[6][7] Squid [8] Netcache (ICPv3) [9] BorderManager FastCache [10] Netscape Proxy Server[11] DeleGate [12] MOWS[13] Inktomi Traffic Server [14] Cisco CacheEngine [15] SkyCache [16] Mirror Image [17] |
|
Cache Array Routing Protocol (CARP) | |
|
Utiliza una función hash para dividir el espacio de direcciones URLs entre grupos de proxy-caché. CARP tiene incluida la definición de una Tabla de Miembros participantes en el grupo de proxy-caché cooperativo, así como las formas de obtener esta información. Un cliente HTTP (proxy o navegador) que implementa CARP v1.0 puede asignar e inteligentemente dirigir solicitudes de un URL hacia uno de los miembros. Gracias a un clasificación eficiente de los URLs entre los miembros, las réplicas en la caché son eliminadas, mejorando aciertos globales.
CARP no es en sí un protocolo, persigue reducir la comunicación entre cachés. |
Microsoft Proxy Server[27] Netscape Proxy Server[28] Squid (parcialmente) [29] |
| Cache Digest | |
| Proporciona de manera compacta información del contenido de su caché a los proxis participantes en su grupo. Cache Digest proporciona de manera compacta información del contenido de su cache a los proxies participantes en su grupo. Una cache utiliza una especie de compendio (Digest) para identificar algún compañero que probablemente pueda tener un objeto del Web buscado. Cache Digests emplea 2 protocolos:1) cómo construir e interpretar un Digest y 2) el procedimiento para intercambiar Digest (cómo solicitarlo a otro proxy, quién puede tenerlo, etc). | Squid2
[29] |
| Hyper Text Caching Protocol (HTCP) | |
| HTCP es un protocolo utilizado para descubrir cachés HTTP y objetos que estén en alguna caché, manipulando conjuntos de cachés HTTP, y analizando su actividad. A diferencia de ICPv2, HTCP incluye las cabeceras, que contienen información muy útil. | Mirror Image
[21] Squid2 (parcialmente)[22] |
| Web Cache Control Protocol (WCCP) | |
| Propietario de Cisco, redirige tráfico Web desde un router al motor de caché de Cisco. WCCP define la comunicación entre los motores Caché de Cisco y routers. Con WCCP, un router redirecciona solicitudes de Web a un motor caché de Cisco (más que intentar al servidor de Web). El router también determina la disponibilidad de las cachés o la presencia de nuevas cachés en el grupo. | Cisco CacheEngine [18][19] |
| CRISP y Relais | |
| Permiten que un grupo de cachés cooperativas compartan un directorio común que lista los documentos "cacheados" por todo el grupo. La principal diferencia está en la representación del directorio. CRISP lo administra centralizadamente mientras que Relais lo replica en cada localidad donde haya una caché. En caso de fallo al buscar un objeto, ambos sistemas revisan el directorio común. Si un compañero lo tiene, le traspasan la solicitud, si no se consulta al servidor original. |
Crispy Squid [CRISP 98] Saperlipopette (Simulador) [32] |
| HTTP/1.1 | |
| Uno de los principales cambios de HTTP/1.0 [34] a HTTP/1.1 [35] es incluir soporte para cachés. Las cabeceras proporcionan a los proveedores de información un soporte que les permita dar directivas de caché. |
Productos HTTP/1.1 |
Tabla 1:Protocolos y estrategias de comunicación entre cachés
A pesar de los buenos resultados encontrados con el uso de proxy-cachés, parece que se ha llegado a un límite, y que mejoras adicionales no van a incrementa de manera sustancial el beneficio. Por ello se han intentado técnicas combinadas de proxy-caché con pre-carga (prefetching) de documentos, que puede proporcionar beneficio sustancial comparado con sólo caché. Sin embargo, el prefetching puede resultar inútil o negativo, debido a que suele fallar muchas veces en sus predicciones (traer documentos que no se van a consultar más, que no han cambiado, que van a cambiar pronto), lo que se refleja en un consumo de ancho de banda innecesario.
Aprovechando la Publicación: Distribución (MWeb)
MWeb es un sistema para el acceso local a un almacén o biblioteca de ciertos documentos Web que se distribuyen de forma muy eficiente hacia los suscriptores (lectores asiduos) de cierto tema o categoría. Cuando un nuevo se publica, se activa una utilidad que lo codifica en formato mime mhtml (multiparte con html y gráficos agrupados), y lo entrega al almacén de news local donde se distribuye por news a los demás almacenes suscritos. Una vez repartido, los clientes podrán acceder a su almacén local donde dispondrán del documento (el más reciente y posiblemente algunas versiones anteriores).
El acceso puede ser automático e invisible para los usuarios (un proxy de web les suministra el documento del almacén), o por consulta al catálogo (un cgi que presenta el contenido del almacén con todas las versiones).
Al separar la distribución de la consulta y publicación se optimiza el uso de los enlaces Internet más saturados, se minimiza el número de copias que viajan del documento (sólo cuando cambia), y el autor sólo tiene que enviar una única copia a la red para llegar a todos los lectores suscritos.
Además los URL que se distribuyen se convierten en nombres persistentes: aunque desaparezca el documento original, todavía podríamos acceder a una o varias versiones del documento del almacén local.
Si los documentos de cierto tema, una colección, se distribuyen en una conferencia moderada, esto permitirá controlar la calidad y volumen de documentos.
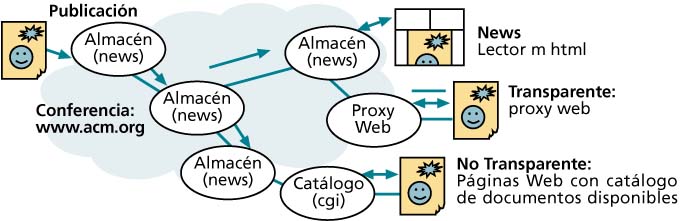
Este modelo está basado en un estudio y en un modelo general para la distribución de contenidos en Internet que se desarrolla en [Lijding 97], donde se discute con mayor detalle el problema.
Se han realizado los siguientes componentes:
- Publicación: A partir del url de un documento, crea un objeto mime mhtml (agrupando texto e imágenes) y lo entrega a una conferencia (nntp), o dirección de correo (smtp).
- Consulta proxy: Módulo de Apache para ofrecer documentos de forma transparente de un almacén de news local con objetos mhtml (hace además de caché)
- Consulta catálogo: CGI que ofrece de cada URL de que dispone, la versión más reciente o muestra el catálogo de todas las versiones disponibles.
Información adicional sobre Mweb (software, documentación, informes) está disponible en la siguiente dirección:http://www.canet.upc.es/mweb.
Publicación
A partir del URL y el nombre de la conferencia donde publicar, se construye un mensaje mime en formato mhtml codificando en el Message-Id el URL principal del documento. Para cumplir con RFC 822, la transformación de forma URL a forma Message-Id es la siguiente:
| URL | Message-Id |
esq://direcc/path/fich.ext | fecha.esq.//path/fich.ext@direcc |
| http://www.upc.es/index.htm |
123456.http.//index.htm@www.upc.es |
Además se añaden al mensaje de news, algunas cabeceras extraídas del documento original con especial cuidado en la fecha de expiración.
Consulta transparente
Si en una jerarquía de caché de Web se configura que para ciertos URL se debe consultar a un servidor Apache con el módulo MWeb cargado...
Cuando un usuario pide alguno de esos URL en su navegador, recibirá del almacén la versión local más reciente si ésta no ha expirado. Si no, seguirá por la jerarquía de caché: el URL de un nivel de caché superior, el URL original, o se le presentará un mensaje para que pueda elegir (según la configuración del módulo MWeb).
Funcionamiento
Se ha desarrollado un módulo de Apache, basado en el módulo proxy, que a partir de un URL lo convierte a la forma Message-Id, y accede a la conferencia correspondiente según el URL y una tabla del fichero de configuración del módulo. Se autentifica si es necesario y utiliza el comando xpat de innd de la forma siguiente:
xpat Message-ID 1- *http.//index.es.html@www.rediris.es>
221 Message-ID matches follow.
2120 <981101085023.http.//index.es.html@www.rediris.es>
2124 <981102085004.http.//index.es.html@www.rediris.es> .
article <981102085004.http.//index.es.html@www.rediris.es>
...Cabecera ...
Mime-Version: 1.0
Content-Type: Multipart/related; boundary="msg-mhtml"; type=Text/HTML
--msg-mhtml
<html>...<IMG SRC="cid:911221453/iconos/portada.gif@www.rediris.es"></html>
--msg-mhtml
Content-ID: <911221453/iconos/portada.gif@www.rediris.es>
Content-Transfer-Encoding: base64
Content-Type: image/gif
R0lGODlhIAKQAPfVAAAAAAAAMwAAZgAAmQAAzAAA/wAzAAAz ...
--msg-html--
El módulo recoge el mensaje mhtml, trata la cabecera comprobando varias cosas, como por ejemplo la fecha de expiración. Se colocan en la caché los objetos (partes del mensaje) con esquema "cid:" que el navegador del cliente solicitará de inmediato tras recibir la primera parte (el texto html).
Catálogo del Almacén
Si se accede al servidor de catálogo, las peticiones de URL se redirigen a un cgi que mira en el almacén si hay alguna versión del documento solicitado. Si nos interesa el URL http://www.rediris.es/index.es.html, del almacén en mosaic.pangea.org podemos preguntar por:
- la versión más reciente: http://mosaic.pangea.org/www.rediris.es/index.es.html
- la lista de versiones disponibles: http://mosaic.pangea.org/www.rediris.es/index.es.html:
- una versión concreta (siguiendo lo propuesto por [Simonson 98]): http://mosaic.pangea.org/www.rediris.es/index.es.html:981116093415
Está previsto que al publicar un documento con metainformación (por ejemplo Dublin Core), pueda incluirse en el mensaje y así poder visitar el catálogo según otras categorías además del URL.
Conclusiones
El Web ha sido la "killer app" de Internet, tanto por su explosivo desarrollo como por su uso explosivo. Los estudios de cachés demuestran que en general porcentajes de acierto por encima del 1/3 son difíciles de conseguir. MWeb puede servir en algunos casos para complementar las cachés.
En ciertas comunidades, hay volúmenes de información (artículos, technical reports, notas, informes, etc.) que se consultan con frecuencia o regularmente, en que los investigadores pueden ser a la vez lectores y autores, que merecen ser guardados, archivados y catalogados. En ese contexto se puede usar con ventajas este modelo de distribución en que se separa el transporte de la consulta/publicación a una biblioteca digital local (MWeb + almacén news) con mecanismos de consulta transparentes o explícitos (cgi catálogo).
Las ventajas más importantes de MWeb están en la accesibilidad instantánea desde el primer acceso (a diferencia de los proxy caché), que el autor sólo ha de proporcionar una única copia del documento, la capacidad de ecualizar el tráfico (trasladar la transferencia a horas valle), eliminar algunas comprobaciones (peticiones HTTP condicionales) la persistencia de los URL y las sucesivas versiones o URL con marcas de tiempo.
El código prototipo de todos los componentes de MWeb puede encontrarse en el URL del proyecto. Esperamos las sugerencias de la comunidad académica, tanto para mejorar el sistema como para montar grupos de distribución de contenido experimentales.
Esperamos contribuir este trabajo al recién creado grupo de trabajo del IETF sobre caché y replicación.
Referencias
http://www.apache.org/
Otros documentos y referencias sobre cachés:
- ftp://ftp.rediris.es/docs/rfc/21xx/2186 "Internet Cache Protocol (ICP) version 2"
- ftp://ftp.rediris.es/docs/rfc/21xx/2187 "Application of ICP v2"
- ftp://ftp.rediris.es/docs/drafts/draft-lovric-icp-ext-01.txt "ICP Extension"
- http://ircache.nlanr.net/Cache/ICP/
- http://excalibur.usc.edu/icpdoc/icp.html
- http://harvest.cs.colorado.edu/
- http://harvest.transarc.com/
- http://squid.nlanr.net/
- http://www.netapp.com/netcache/
- http://www.novell.com/bordermanager/fastcache/
- http://www.netscape.com/comprod/proxy_server.html
- http://wall.etl.go.jp/delegate/
- http://mows.rz.uni-mannheim.de/mows/
- http://www.inktomi.com/products/traffic/
- http://www.cisco.com/warp/public/751/cache/
- http://www.skycache.com/
- http://www.mirror-image.com/
- http://www.cisco.com/univercd/data/doc/netbu/hardware/webcache/webcache.htm
- http://www.cisco.com/warp/public/751/cache/cds_ov.htm
- ftp://ftp.nordu.net/internet-drafts/draft-vixie-htcp-proto-03.txt
- http://www.mirror-image.com/
- http://squid.nlanr.net/
- ftp://ftp.nordu.net/internet-drafts/draft-vinod-carp-v1-03.txt
- http://www.eu.microsoft.com/proxy/guide/CarpWP.asp
- http://egg.microsoft.com/carp/
- ftp://ftp.nordu.net/internet-drafts/draft-vinod-carp-v1-03.txt
- http://www.microsoft.com/proxy/
- http://www.netscape.com/comprod/proxy_server.html
- http://squid.nlanr.net/
- http://squid.nlanr.net/Squid/FAQ/FAQ-16.html
- http://wwwcache.ja.net/events/workshop/31/rousskov@nlanr.net.ps
- ftp://ftp.rediris.es/docs/rfc/19xx/1945 HTTP/1.0
- ftp://ftp.rediris.es/docs/rfc/20xx/2068 HTTP/1.1
Leandro Navarro, Victor J. Sosa
 leandro [at] ac [dot] upc.es
vjsosa [at] ac [dot] upc.es
leandro [at] ac [dot] upc.es
vjsosa [at] ac [dot] upc.esUniversitat Politècnica de Catalunya
http://www.canet.upc.es/mweb