
 Diego R. López y Javier Masa
Diego R. López y Javier Masa Tradicionalmente, los enemigos naturales de los que nos dedicamos a esto de las redes han sido de dos clases: nuestros usuarios y nuestros jefes. Pero desde que la WWW se ha transformado en un medio básico de presencia institucional y de difusión de información, se han sumado a ellos nuevos elementos: los que tienen que ver con cuestiones de diseño e identidad corporativa y los que se dedican a la catalogación de la información. Por abreviar, llamémosles diseñadores y documentalistas.
Cuando un servidor Web contiene un número de páginas suficientemente grande cualquier cambio en el aspecto o en la organización de las páginas, por pequeño que sea, suele suponer una verdadera pesadilla para el administrador del servidor. Hay mecanismos por ahí que, de una manera u otra, todos hemos empleado alguna vez (los server-side includes de Apache o utilizar PHP masivamente, por ejemplo) para tratar de aliviar estos problemas. También existen servidores comerciales que (al menos en teoría) permiten definir un aspecto común para todo el servidor. Pero cualquiera de estas soluciones supone utilizar mecanismos adicionales al HTML, lo que los hace poco portables a diferentes arquitecturas y entornos. Esto en cuanto a los diseñadores.
Veamos el frente de los documentalistas. Es un lugar común en toda la Internet la necesidad de encontrar formas más eficaces de buscar información. Para que las búsquedas de información puedan realizarse de forma más eficiente y directa, es necesario disponer de información sobre la información: metainformación. Sin embargo, no es sencillo que cualquier persona que publica un documento a través de la WWW tenga en cuenta todas las sutilezas de clasificación de la información que contiene. De hecho, es aún más difícil convencerla de que, si los criterios de clasificación cambian por cualquier motivo, actualice la metainformación de todos los contenidos que tenga publicados hasta ese momento.
Para resumir, todo el esfuerzo sobre el Webber nació como un mecanismo de autodefensa frente a nuevos enemigos naturales y con dos objetivos básicos, independientes pero complementarios. Por un lado, facilitar la integración de la información disponible en los servidores Web, proporcionando mecanismos para que esta información pueda ser presentada de manera coherente y uniforme. Por otro, simplificar la asociación de metainformación con los datos contenidos en el servidor. Webber es un producto de la selección natural y, por tanto, adaptado para la (nuestra) supervivencia ¡loado sea Darwin!
¿De dónde venimos?
La misma complejidad de la información contenida en los servidores Web, tanto en fuentes de información como en la estructura de la información en sí misma, constituye un elemento que dificulta una oferta de información coherente y uniforme a través de ellos. Esto es especialmente aplicable a organizaciones de tamaño pequeño o medio, o que no estén directamente orientadas al sector de la informática y las telecomunicaciones.Típicamente, cuando un organización decide ofrecer información a través de servicios de red, realiza un esfuerzo inicial grande para poner a punto estos servicios que, en el mejor de los casos, incluye mecanismos internos para que las diferentes unidades de la organización vayan publicando la información que produzcan. A medida que se va añadiendo nueva información a los servidores y se van incorporando nuevas fuentes, el resultado habitual es una dispersión en los formatos en que se presenta, junto con efectos de oscurecimiento de la oferta de información: el acceso a ciertos datos queda oculto en la estructura de los servidores, sin que puedan ser encontrados de una manera directa por los potenciales usuarios de los mismos. Por otro lado, cualquier cambio general en lo relativo a organización de la información, imagen corporativa, etc. va haciéndose más y más complicado conforme la cantidad de datos es mayor. En general, una actualización del aspecto y modo de acceso a la información puede llegar a suponer un coste muy superior al del establecimiento inicial del servicio. En organizaciones grandes y con el personal adecuado, las situaciones de este tipo pueden, al menos, ser aliviadas mediante mecanismos de control establecidos por los propios administradores de los servidores de información.
Existen en el mercado un gran número de soluciones para facilitar la publicación de información a través de Web, tanto de documentos [1], [2], [3] como de metadatos [4], [5], [6]. Con el uso de estas herramientas, resulta relativamente simple incorporar la información que la organización vaya generando a los servidores de red. Sin embargo, se echan en falta mecanismos para mantener esta información conforme a ciertos parámetros de presentación, organización y accesibilidad, así como para efectuar cambios simultáneos en estos parámetros cuando así se requiera.
Por lo que respecta a la metainformación, conviene en primer lugar señalar que es un concepto en el que se está trabajando muy activamente, tanto en las redes académicas[7], [8], como en las comerciales. Es importante notar que la introducción de metainformación directamente durante la fase de edición de los datos o inmediatamente antes de su publicación en el servidor (lo que constituye el enfoque tradicional) implica correr riesgos similares a los que describíamos antes para el mantenimiento del formato y organización de la información. A medida que la cantidad y número de fuentes de información aumenta, la tendencia a la dispersión puede llegar a crear una situación en la cual una búsqueda basada en metadatos tenga tan poco valor como las puramente textuales. Ni que decir tiene que el mantenimiento de esta metainformación presenta problemas aún mayores que el de la presentación de la información en sí misma.
La relación entre los mecanismos de control y mantenimiento de los formatos de la información y los de asignación de metainformación implica tener en cuenta dos aspectos fundamentales de esta última. En primer lugar, una cantidad apreciable de la metainformación asociada con unos determinados datos se corresponde, de manera natural, con la organización misma de la información. Tal es el caso de metadatos como la afiliación del o los autores, la unidad organizativa a la que pertenecen o la clase de información que se ofrece. A la vez que se dota de una apariencia determinada a todos los documentos que se encuentran en un lugar del árbol de páginas del servidor es posible introducir una cantidad apreciable de metainformación.
En segundo lugar, existen otro tipo de metadatos que están implícitamente asociados con la información, como es el caso de las palabras clave asociadas a un documento. Si bien este tipo de metainformación suele ser proporcionada directamente por los autores, existen situaciones en las que resultaría conveniente disponer de un sistema de extracción de este tipo de datos que simplificara la asignación de esta clase de metadatos. La estructura relativamente formalizada de lenguajes como HTML permite que estas técnicas de extracción no deban ser excesivamente sofisticadas, de manera que se exploten las regularidades impuestas por los formatos de presentación a la hora de extraer esta clase de metainformación.
Esencialmente, al modificar el aspecto de la información aprovecharemos el proceso necesario para, en paralelo, extraer y asignar metainformación a la misma. Y lo que es más importante: los mecanismos para ello serán repetibles y configurables. De esta manera la calidad de la información no se verá resentida a medida que aumenten su cantidad y su diversidad.
Por último, en un país con cuatro lenguas oficiales y en un mundo con una "lengua oficial" que no es ninguna de las otras cuatro, algo también importante es el soporte multilengua. La negociación de contenido entre el cliente y el servidor Web es algo que, en la mayor parte de los casos, no se utiliza. En la práctica, lo usual es utilizar enlaces a diferentes versiones del mismo documento. Es evidente que esto constituye también metainformación y que si el sistema de control de la presentación es capaz de detectar las versiones de un documento en diferentes lenguajes y enlazarlos automáticamente, nos defenderemos también de otros enemigos (¡y de los más peligrosos!) que olvidamos en la introducción: los puristas del lenguaje.
¿En dónde estamos?
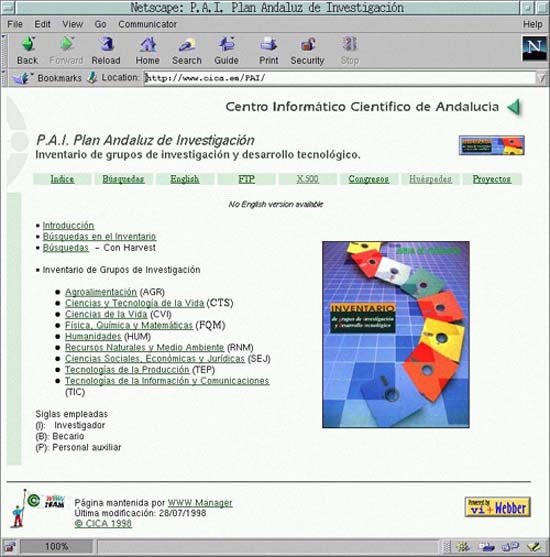
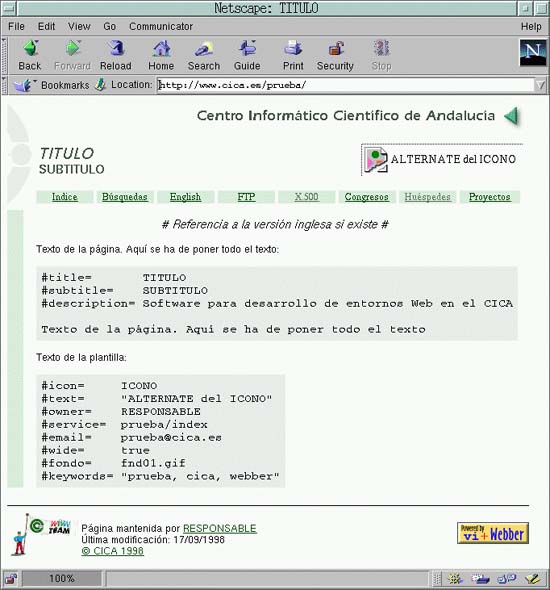
En la actualidad existe un Webber en el que pensamos como el prototipo que demuestra la viabilidad de la aproximación como la que discutimos aquí. Nació a primeros de 1997, cuando Javier Puche y Rubén Martínez pensaron en construir un script Perl para incorporar una apariencia homogénea a cada página HTML en el servidor de RedIRIS, que a la sazón estaba en uno de esos procesos de cambio por cuestiones de identidad corporativa.Las páginas se escribían sin cabeceras ni pies de página ya que se incorporarían posteriormente. Cada página contenía HTML más unas variables y Webber generaba otra página con el mismo código más el código que hacía que las páginas tuviesen la misma apariencia. Más tarde se fueron añadiendo opciones para que se pudiesen incorporar distintos elementos dependiendo de las variables contenidas en el fichero origen o en unas plantillas. También se incorporó la facilidad de detectar si existía una página en otro idioma para generar un enlace hacia la misma o un texto indicando la no existencia de la misma.
Para proporcionar todas estas facilidades hubo que cambiar la nomenclatura de los ficheros del servidor. Los nombres de los ficheros en castellano cambiaron de "fichero.html" a "fichero.es.html" y en inglés del nombre que tuviesen a "fichero.en.html". De esta forma, si se procesaba el fichero "prueba.es.html" se podía hacer de forma automática una comprobación de la existencia del fichero "prueba.en.html" para incorporar un enlace hacia él. Los nombres de los ficheros originales con el código HTML origen eran de la forma ".fichero.es" o ".fichero.en".
Más adelante se planteó la posibilidad de usar esta herramienta para facilitar la indexación del servidor y de ahí se llegó a la idea de modificar Webber para que incorporase metainformación a las páginas. Para ello se usaban los ficheros de plantilla para escribir unos valores comunes a todas las páginas que se tendrían que incorporar posteriormente. Los valores específicos para cada página se escribían como variables en los ficheros origen. Una vez incorporada la metainformación en todas las páginas del servidor se pudo realizar un indexado del mismo usando Harvest. La ventaja del programa era que si cambiaba la jerarquía de catalogación no era necesario cambiar todas las páginas. Bastaba con modificar Webber para que lo hiciese en todas.
El CICA se interesó en este software ya que también se había iniciado un gozoso proceso de cambio en su servidor. También era necesario indexarlo usando metainformación para participar en el Piloto de indexación por red IRIS-INDEX. RedIRIS proporcionó el script para que el CICA lo usase. Tras ser modificado para que tuviese la apariencia corporativa de sus páginas y para ser capaz de manejar algunas variables más, es la herramienta básica para publicar información en el servidor Web del CICA[9]. Algunos resultados de ese trabajo puede verse en las Figuras 1 y 2 que están incluidas en este artículo.
Para facilitar el trabajo del grupo IRIS-INDEX se ha creado también la herramienta MetaWebber [10]. Esta herramienta no cambia nada del aspecto de la página. No necesita una página origen especial como Webber. Lo único que hace es tomar una página HTML generada con cualquier programa e incorporar tags HTML con metainformación corporativa. Para ello se basa en un fichero de plantilla donde se almacena dicha metainformación. Estos ficheros se guardan en cada directorio y afectan a todos los ficheros que estén bajo ese directorio. La metainformación almacenada por esta herramienta no es extraída de la página, sino que solamente se utiliza la almacenada en las plantillas, que es la misma para todos los ficheros de un directorio.
Otra herramienta derivada del Webber se está utilizando para incorporar metainformación en las páginas de las Comunidades Virtuales de Usuarios de RedIRIS [11].
¿A dónde vamos?
Partiendo de las premisas que veíamos anteriormente y vista la viabilidad de las mismas con la versión actual del Webber, presentamos un proyecto al Programa Nacional de Aplicaciones y Servicios Telemáticos, con el título "Sistema de integración y extracción de metainformación para servidores de red" y en colaboración con RedIRIS y AlAndalus-SAR como EPOs. El proyecto ha sido recientemente aprobado por la CICYT y estamos empezando a trabajar en él. Esencialmente, pretendemos con él aumentar significativamente la potencia del actual Webber, dotarlo de una flexibilidad de la que ahora carece y darle inteligencia y capacidad de proceso lingüístico a la hora de incorporar la metainformación. El proyecto tiene una duración de dos años y los objetivos básicos del sistema que debe salir de él son:
- Ofrecer mecanismos de configuración del formato y de asignación de la metainformación, con capacidad de definición de características globales a todo el servidor Web y de particularización para ciertas partes del mismo, por medio de mecanismos de herencia. El procedimiento básico de configuración estará basado en plantillas que definirán el aspecto general de la información. Un ejemplo de lo que, en la fase de definición en la que estamos, podrían ser los ficheros de configuración se encuentra en el listado que aparece más adelante.
- El sistema de extracción de metainformación ofrecerá medios para que el usuario valide sus resultados y controle su funcionamiento por medio de asignaciones cualitativas, sin necesidad de requerir al usuario un conocimiento detallado del lenguaje en que se ha escrito la información (típicamente, HTML).
- Los contenidos dinámicos del servidor podrán ser también procesados por un módulo específico del sistema, de manera que el formato sea coherente para toda la información ofrecida por el servidor.
- De manera paralela al procesado de la información, se generarán índices tanto para facilitar la búsqueda por parte de los usuarios como para simplificar las tareas de gestión de la información por parte de los administradores. Estos índices podrán almacenarse en formatos estándar (como SOIF [12] , [13] para facilitar la interconexión de los índices y la construcción de metaíndices.
- Dada la diversidad de plataformas hardware y sistemas operativos sobre los que se ejecutan los servidores de información, el sistema será desarrollado utilizando un lenguaje neutral y capaz de ser ejecutado por prácticamente cualquier plataforma, como Java.
# # This is Webber 1.1a1 configuration file. # Copyright... # # Directory definitions # # Source directory tree for the execution of Webber. # If not set, the current working directory when invoking Webber will be used. SourceRoot = "/usr/local/WWWsrc" # # Destination directory tree for the execution of Webber. # If not set, the current working directory when invoking Webber will be used. # The same tree structure will be mapped from SourceRoot to DestinationRoot DestinationRoot = "/usr/local/WWW" # # These directories will be directly copied from the source tree to the destination tree # when Webber is invoked with option "-a". Use it, for example, with directories # containing images, sounds, applets, etc. Paths are relative to SourceRoot. PreciousDir = "images","sound" # # File identification # # File containing values of Webber variables in each source directory. VarFile = ".webber" # # Template HTML file for building pages in each source directory. TemplateFile = "webber.html" # # When Webber is invoked on a directory, or with the "-r" or "-a" options, process only # those files with names starting with SourcePrefix. The corresponding output file name # will have it substituted by the adequate DestinationPrefix. SourcePrefix = "." DestinationPrefix = "" # # When Webber is invoked on a directory, or with the "-r" or "-a" options, process only # those files with names ending with SourceSuffix. The corresponding output file name # will have it substituted by the adequate DestinationSuffix. SourceSuffix = ".wb",".pwb" DestinationSuffix = ".html",".phtml" # # When Webber is invoked on a directory, or with the "-r" or "-a" options, files starting # with PreciousPrefix or ending with PreciousSuffix will be directly copied from the # source tree to destination. PreciousPrefix = "" PreciousSuffix = ".gif",".jpg",".class" # # Multilingual support # # Definitions for the different languages supported by Webber in this server. # They contain the link name of the language (as it will displayed in the documents, # using the HTML code in it), the meta name for the language and a list of extensions # that identify a file as using the language. # Language1 is assumed to be the "main language" of the server. # Files without language extensions are assumed to use the main language. # If no language or only Language1 is defined, multilingual support will not be # available. Language1 = "Español","es",".es" Language2 = "<img src=\"eFlag.gif\" alt=\"English\">","en",".en",".in*"El objetivo final es que el Webber sea un sistema flexible, capaz de correr en cualquier plataforma, capaz de integrarse con un amplio conjunto de herramientas de desarrollo y publicación de contenidos y que permita los responsables de los servidores de información de una organización:
- Simplificar la definición y mantenimiento de la estructura con que la información es presentada por los servidores.
- Descentralizar los procedimientos de publicación de nueva información, garantizando a la vez un aspecto coherente de la misma.
- Aumentar la calidad de la información ofrecida y facilitar su localización a los potenciales usuarios.
Referencias:
- http://home.netscape.com/communicator/guide.html#composer
- http://www.microsoft.com/frontpage/
- http://www.softquad.co.uk/products/hotmetal/
- http://www.ukoln.ac.uk/metadata/dcdot /
- http://www.ub.lu.se/metadata/DC_creator.html
- http://vancouver-webpages.com/VWbot/mk-dublin.html
- http://www.rediris.es/si/iris-index/
- http://www.terena.nl/working-groups/wg-isus/task-forces/tf-chic/
- http://www.cica.es/webber/
- http://www.rediris.es/si/iris-index/herramientas/metawebber/
- http://www.rediris.es/cvu/
- http://www.tardis.ed.ac.uk/harvest/
- http://harvest.transarc.com/afs/transarc.com/public/trg/Harvest/user-manual/node51.html
Diego R. López
CICA
Responsable Área de Aplicaciones de Red
 drlopez [at] cica [dot] es
drlopez [at] cica [dot] es
Javier Masa
RedIRIS
Sistemas de Información
javier [dot] masa [at] rediris.es