
 Íñigo López Cía
Íñigo López Cía Introducción
En la actualidad las bibliotecas y centros de documentación disponen de bases de datos documentales donde se encuentran catalogados sus fondos. Este sistema permite generar índices que facilitan las tareas de búsqueda de información en base a criterios diversos. Sin embargo, el acceso a estas bases de datos se realiza normalmente a través de interfaces rudimentarios de tipo textual, no aptos para usuarios sin conocimientos. Además, es necesario desplazarse hasta un terminal de consulta ubicado en el propio centro de documentación para efectuar las búsquedas.Una vez realizada la búsqueda obtendremos como resultado las fichas bibliográficas correspondientes a los documentos deseados, que probablemente incluirán una referencia a la localización física de los mismos. Posteriormente será necesario pedir el documento al encargado del centro de documentación, confiando en que se encuentre disponible.
Un primer paso hacia la simplificación de este tedioso proceso es permitir el acceso remoto a las bases de datos, pudiendo realizar las búsquedas desde terminales distantes. En este sentido se han desarrollado dos soluciones contrapuestas que se analizan más adelante: el protocolo Z39.50, ampliamente utilizado en bibliotecas de los Estados Unidos desde hace ya varios años, y pasarelas entre servidores WWW y los programas gestores de bases de datos. Cada sistema tiene sus ventajas y sus inconvenientes, pero son un gran paso adelante y permiten en la actualidad realizar búsquedas en bibliotecas remotas utilizando la red Internet. Sin embargo, por lo general estos sistemas no permiten recuperar una copia digital del documento deseado, por lo que el último eslabón del proceso queda sin cubrir.
Lógicamente, el siguiente paso sería permitir la recuperación de los documentos en sí, no sólo sus fichas. La idea es realizar una digitalización previa de todos los fondos de un centro de documentación y almacenarlos en dispositivos magnéticos u ópticos. A las fichas bibliográficas se les añade un campo con metainformación acerca de la localización de la copia digital del documento (por ejemplo un URL), el tipo de contenido (texto, imagen, sonido, vídeo, etc.), calidad de la digitalización, sintaxis de presentación, etc. Los documentos originales pueden ser archivados en un lugar seguro para evitar su deterioro (algo muy común en operaciones de fotocopiado) o incluso eliminados si carecen de valor.
Acceso remoto a índices bibliográficos
El acceso remoto a índices bibliográficos puede implementarse mediante la utilización de un protocolo de búsqueda y recuperación de información como Z39.50, o mediante otros métodos más populares en Internet como HTTP.
Z39.50
Z39.50 es un protocolo con gran difusión en bibliotecas de Estados Unidos. Permite realizar búsquedas complejas en las bases de datos de un servidor, y posteriormente recuperar los registros que coinciden con dichas búsquedas. Es un protocolo orientado a conexión, rico en contexto, donde el servidor almacena el estado de la sesión que mantiene el cliente.
Para identificar los campos que contiene una base de datos se utiliza el concepto de attribute set. Un attribute set asigna identificadores únicos a los distintos campos que puede contener una base de datos bibliográfica, tales como título, autor, fecha de publicación, editorial, ISBN, etc. De esta forma, se oculta el formato interno de la base de datos, y el cliente sólo necesita conocer qué attribute set utiliza el servidor. Esto es además negociable en la fase de inicialización de la conexión. Existen distintos attribute sets normalizados, entre los que destaca por su amplio uso en bibliotecas el bib-1.
Asimismo se define el formato en el que el servidor envía los registros bajo petición del cliente. El formato más común se denomina MARC, existiendo versiones internacionales del mismo: US-MARC, UK-MARC, etc.
Z39.50 está especificado mediante la notación ASN.1 (Abstract Syntax Notation), y su sintaxis de transferencia son las reglas de codificación básicas o BER (Basic Encoding Rules) de esta notación. Este es precisamente uno de los grandes inconvenientes a la hora de implementar el protocolo, ya que se trata de una sintaxis extremadamente compleja, sobre todo desde el punto de vista de Internet, donde normalmente las sintaxis de transferencia de sus protocolos son de tipo textual. Actualmente está en debate la necesidad de crear una nueva versión de Z39.50 simplificada (denominada Z-lite) que elimine esta complejidad, pero existe una gran oposición a esta iniciativa desde el mundo de los bibliotecarios.
HTTP
HTTP es un protocolo ampliamente utilizado en Internet, gracias al gran éxito que ha supuesto el World-Wide Web como medio de publicación de información. Justo al contrario del caso anterior, se trata de un protocolo no orientado a conexión, muy sencillo. El cliente realiza una petición al servidor, éste contesta enviando la información solicitada, y a continuación cierra la conexión. Si el cliente desea hacer peticiones posteriores, necesita abrir una nueva conexión con el servidor.
Este método claramente no es el más apropiado para el acceso a bases de datos, donde es necesario mantener el concepto de sesión. Sin embargo, a través de pasarelas CGI en el servidor WWW y el empleo de variables ocultas en formularios HTML, es posible simular sesiones de acceso a bases de datos, con la ventaja de que los clientes potenciales son todos aquellos que dispongan de un navegador WWW. En cualquier caso, la implementación de la pasarela será distinta para cada caso particular de base de datos, así como el interfaz de acceso al usuario.
DBAP
Analizando en profundidad los dos protocolos anteriores, se llega a la conclusión de que sería deseable la utilización de un protocolo híbrido que tuviera lo mejor de ambos, siendo tan potente como Z39.50 pero tan sencillo como HTTP. De aquí surge el protocolo DBAP, DataBase Access Protocol.
DBAP es un protocolo orientado a conexión con sintaxis de transferencia textual. Soporta las siguientes operaciones: INIT, EXPLAIN, SEARCH, SORT, RETRIEVE, UPDATE y CLOSE.
- INIT: inicializa la sesión permitiendo que el cliente se identifique y negocie parámetros con el servidor,
- EXPLAIN: petición de metainformación al servidor acerca de sus características y de las propiedades de sus bases de datos,
- SEARCH: realiza búsquedas en determinadas bases de datos del servidor,
- SORT: ordena los resultados de una búsqueda,
- RETRIEVE: petición de registros pertenecientes a un resultado de una búsqueda anterior,
- UPDATE: permite realizar actualizaciones en las bases de datos,
- CLOSE: finaliza la sesión.
Una de las características más importantes de DBAP es su compatibilidad con la arquitectura actual de la red Internet, donde entran en juego elementos tales como proxies, túneles, cortafuegos, etc.. Es posible que un servidor DBAP permita realizar búsquedas sobre bases de datos externas al mismo, redirigiendo las operaciones al servidor adecuado. De esta manera se puede configurar un ordenador para que actúe como proxy DBAP, de la misma forma que se hace en HTTP. Esto también permite colocar un servidor DBAP dentro de una zona segura dentro de una organización, detrás de un cortafuegos. El servidor DBAP es invisible desde el exterior de la organización, y el cortafuegos hace de proxy DBAP redirigiendo al servidor las peticiones. De esta forma, podemos estar seguros de que no se producirán ataques sobre nuestro servidor, que contiene nuestras valiosas bases de datos.
Digitalización de documentos
Antes de proceder a la digitalización de nuestros fondos es necesario hacer un estudio sobre la calidad que obtendremos tras esta operación. La calidad de la copia digital del documento depende fundamentalmente de dos factores: la resolución y el número de colores empleados.
Calidad de digitalización
La resolución indica el número de muestras que se toman del documento por unidad de longitud. Suele medirse en puntos por pulgada (PPP o DPI, Dots Per Inch). Los escáners actuales permiten alcanzar resoluciones de hasta 1.200 PPP sin ningún problema, por lo que no estaremos limitados en este sentido. La elección ideal es digitalizar el documento a la misma resolución a la que fue impreso originalmente, para no perder información.
El número de colores también influye en gran medida en la calidad final obtenida. La mejor elección también es en este caso utilizar el mismo número de colores que contiene el documento original. Las imprentas por lo general utilizan sólo dos colores, blanco y negro, variando la densidad de los puntos (mediante técnicas de dithering) para simular gamas de grises. Por este motivo, es suficiente para la mayoría de los documentos realizar una digitalización monocromática. En el caso de documentos impresos en filmadoras, que realmente utilizan una escala amplia de colores, se deberá utilizar una gama de 256 grises o bien 16 millones de colores, según se trate de documentos en blanco y negro o a color.
En nuestro caso particular, el 99% de los documentos son del primer tipo, por lo que es suficiente utilizar como parámetros de digitalización una resolución de 600 puntos por pulgada y un esquema de color monocromático. Podemos asegurar que las diferencias entre el original y una impresión de su copia digital son inapreciables.
Formato de almacenamiento
En la actualidad existen multitud de formatos gráficos, con características propias que los hacen más apropiados para determinados casos. El que mejor cumple nuestras necesidades es el formato TIFF, Tagged Image File Format. Entre sus características cabe destacar:
- permite almacenar múltiples páginas dentro de un mismo archivo,
- incluye información acerca de la resolución utilizada al digitalizar la imagen,
- permite utilizar distintos algoritmos de compresión de la imagen para reducir el tamaño del fichero resultante.
| Tipo | Resolución | Colores | Compresión | Tamaño | |
|---|---|---|---|---|---|
| Normal | 600 ppp | monocromo | FAX grupo 4 | 100 kb | |
| Fotografía b/n | 200 ppp | 256 grises | JPEG | 800 kb | |
| Fotografía color | 200 ppp | 16 millones | JPEG | 1.000 kb | |
Formato de transmisión
El formato para transmitir los documentos digitales debe ser comprendido por el cliente para su correcta presentación al usuario. Por lo tanto, se impone la elección de un formato estándar para no limitar el número de clientes que puedan acceder al servicio. Como se explica más adelante, los formatos utilizados son TIFF y PostScript.
Para sacar el máximo provecho al sistema, es indispensable tener en cuenta las capacidades de presentación de documentos del cliente al usuario final. Básicamente, podemos pensar que el usuario desea ver los documentos en la pantalla, o bien imprimirlos en su impresora para su posterior lectura. Obviamente, la resolución empleada por un monitor es inferior a la de una impresora, y el número de colores es generalmente superior. Si el cliente comunica al servidor cuales son las características del dispositivo que empleará para la presentación, el servidor será capaz de proveer una imagen optimizada para ese dispositivo. Por lo tanto, el cliente debe comunicar en principio tanto la resolución de su dispositivo como el número de colores que acepta. Valores típicos pueden ser 75 ppp y 16 millones de colores para monitores y 300 ppp y monocromo para impresoras, aunque por supuesto estos valores varían de un cliente a otro.
Si el dispositivo final de presentación es el monitor, el servidor se encargará de reducir la resolución de la imagen antes de su transmisión. Esta reducción de resolución implica obviamente una pérdida de calidad. Para reducir este efecto, en el caso de imágenes monocromas, se aumenta la gama de colores a una escala de 256 grises, obteniendo una resolución virtual superior a la del monitor, y mejorando notablemente la representación de la imagen en pantalla. El formato de transmisión en este caso es TIFF con compresión DEFLATE.
Si el destino del documento es la impresora, la transmisión se realiza a plena resolución (sin modificar el original) para aprovechar al máximo la capacidad de la impresora. El servidor realiza una conversión del formato TIFF a PostScript, de manera que puede ser enviado directamente a la impresora.
Funcionamiento del sistema
El sistema digital de archivo y recuperación de información se compone de tres bloques: el servidor DBAP, el almacén de información digital, y el cliente DBAP, que en una primera fase se implementará mediante una pasarela en el servidor de Web (ver figura).
Servidor DBAP
El servidor de DBAP reside en la máquina que tiene instalada la base de datos documental BRS. Está escuchando en un puerto determinado, atento a peticiones de conexión de ordenadores remotos. Cuando detecta una petición de conexión, analiza la dirección de origen del cliente, y decide si acepta dicha conexión (puede configurarse para rechazar automáticamente determinadas direcciones IP).
Una vez que la conexión ha sido establecida, el servidor espera a recibir peticiones del cliente. Para cada una de ellas, efectúa las operaciones correspondientes en la base de datos mediante un módulo de acceso a BRS y devuelve una respuesta al cliente con la información apropiada. Además, va guardando el contexto de la sesión, de forma que el cliente puede hacer referencia en operaciones posteriores a búsquedas previamente realizadas. Cuando el cliente finaliza la sesión mediante la operación CLOSE, el servidor cierra la conexión y se pierde la información de contexto. El servidor está siendo diseñado modularmente, de forma que sea sencillo instalar módulos adicionales para acceder a bases de datos de distintos fabricantes.
Un servidor DBAP también puede ser configurado como proxy para permitir el acceso a sus clientes a bases de datos de otros servidores. Si un cliente realiza una operación sobre una base de datos externa al servidor, éste efectúa la operación directamente sobre el servidor adecuado, y redirige la respuesta de nuevo al cliente.
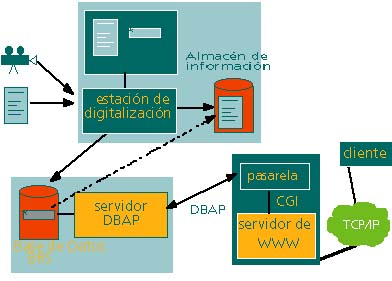
Estación digitalizadora
La estación digitalizadora y almacén de información es una estación de trabajo Indy de Silicon Graphics. El proceso de digitalización de documentos se lleva a cabo mediante el programa scanweb, que es una pasarela CGI del servidor de WWW. El proceso es el siguiente: primero se selecciona el documento que se quiere digitalizar, que ha sido previamente dado de alta en la base de datos en el proceso de catalogación; posteriormente se realiza la digitalización del documento y su almacenamiento; finalmente, se actualiza el registro de la base de datos para que incluya la localización (URL) de la copia digital. Para las tareas de búsqueda del documento a digitalizar y actualización de la base de datos, el programa scanweb utiliza los servicios de nuestro cliente DBAP implementado también como pasarela CGI.
Un cliente DBAP puede acceder directamente a una copia digital del documento a través de su URL, normalmente mediante el protocolo HTTP, obteniendo una copia exacta de la información que está almacenada. Sin embargo, se ha desarrollado otra pasarela CGI, denominada resample, encargada de servir los documentos al cliente optimizados para su dispositivo de presentación. El cliente comunica al programa resample qué documento quiere y la resolución a emplear. El programa realiza la conversión de resolución y formatos (si procede) y envía el resultado al cliente.
En ambos casos existen ficheros de configuración para permitir o denegar el acceso a determinadas direcciones IP o a determinados usuarios con el empleo de contraseñas.
Cliente DBAP
Un cliente DBAP sería un programa instalado en el ordenador del usuario final, que entendiera el protocolo DBAP y se conectara directamente a servidores DBAP. De momento, dicho cliente se está desarrollando como una pasarela CGI en el servidor de Web de Fundesco, para permitir que cualquier usuario con un navegador de Web pueda acceder al sistema.
La pasarela debe realizar una conversión del contexto de HTTP al de DBAP y viceversa. Asimismo debe emular una sesión mediante la utilización de variables ocultas en formularios, ya que el concepto de sesión se mantiene sólo entre la pasarela y el servidor de DBAP, pero se rompe entre el servidor de Web y el cliente.
Esta pasarela primero se conecta al servidor DBAP y realiza una operación de tipo EXPLAIN, obteniendo información acerca de las bases de datos disponibles. Permite seleccionar una o varias bases de datos y efectuar una búsqueda sobre ellas, utilizando un lenguaje de búsqueda definido. Posteriormente muestra un listado resumen de los documentos que satisfacen nuestro criterio de búsqueda, y seleccionando cualquiera de ellos accedemos a su ficha bibliográfica. Si el documento ha sido digitalizado, también tendremos la opción de mostrar su contenido en pantalla o bien recibir un fichero postscript que puede ser enviado directamente a nuestra impresora para imprimir el documento sin pérdida de calidad.
También está en estudio el desarrollo de un cliente DBAP que realmente resida en el ordenador del cliente. Puede tratarse de una aplicación propiamente dicha, un plug-in para un navegador de WWW o un programa en Java que fuera descargado del servidor DBAP. Utilizando un cliente de este tipo el concepto de sesión se mantendría realmente extremo a extremo y la comunicación entre cliente y servidor sería más eficiente, reduciendo tiempos de espera en las operaciones de búsqueda.
Iñigo López Cía
FUNDESCO
Dpto. de Redes
 ilopez [at] fundesco [dot] es
ilopez [at] fundesco [dot] es